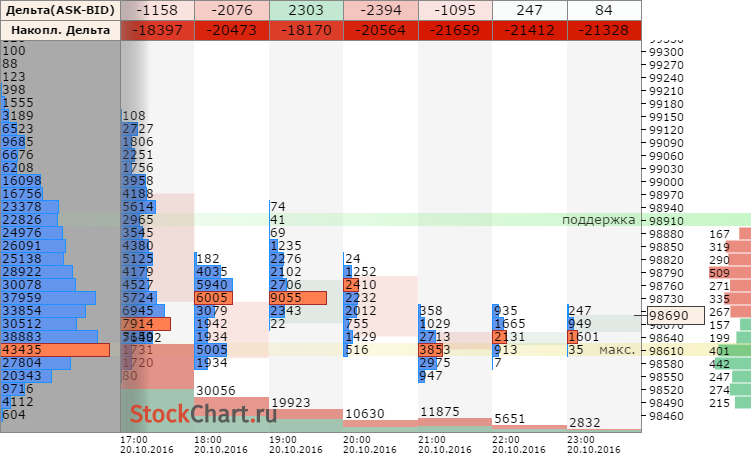
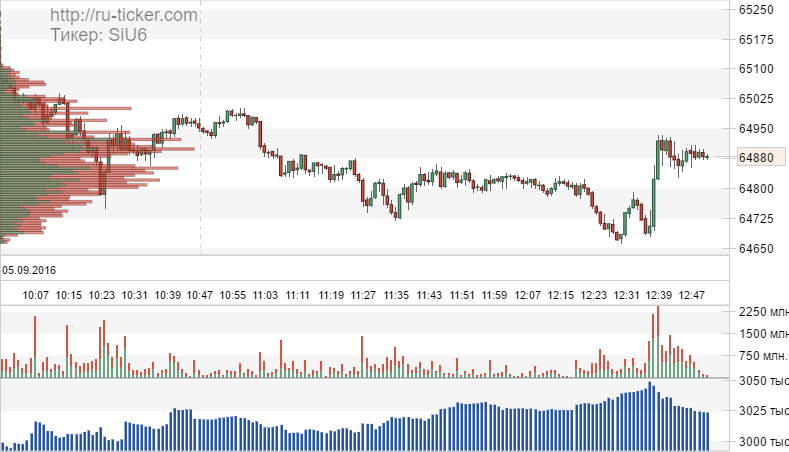
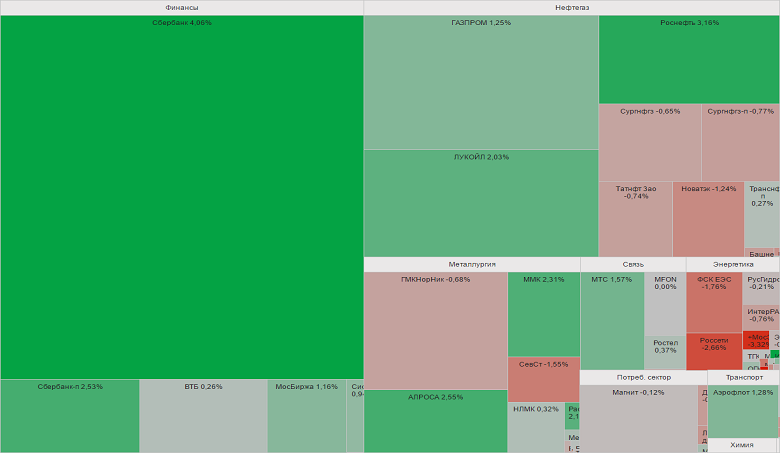
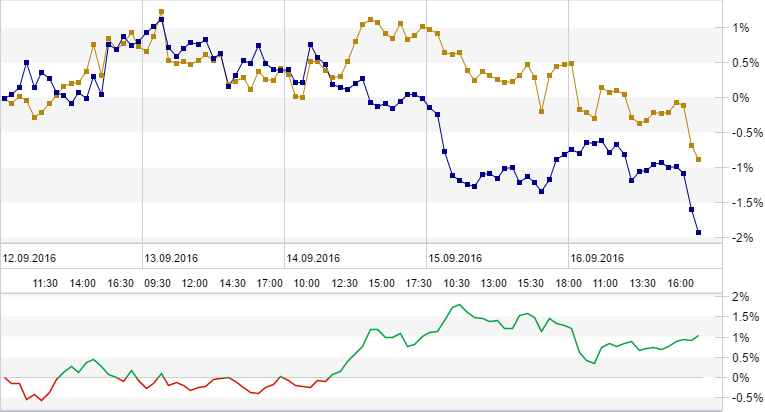
 | | | |||||||||||
|
|
||||||||||||
| | | |||||||||||||||
|
|
||||||||||||||||



Техническая поддержка
ONLINE
| | | |||||||||||||||||
|
|
||||||||||||||||||
"Build an AI startup in 2025!" - Professional AI agent developer
ruticker 04.03.2025 15:24:44 Recognized text from YouScriptor channel David Ondrej
Recognized from a YouTube video by YouScriptor.com, For more details, follow the link "Build an AI startup in 2025!" - Professional AI agent developer
**This is Jason.** You probably know him as AI Jason. He's a professional AI agent builder and product designer. In this podcast, we talk about how to build an AI startup, how Owan is making people thousands of dollars, and how to build anything with AI. If you want to turn your AI idea into a startup, this video is perfect for you, so watch until the end. **So Jason, what advice do you have for people who want to build their own AI startup?** I think probably there are a few things. There are a lot of potential ideas about what you can actually build with AI or with AI workflows. First, just try to find a problem that you personally experience a lot—something high-frequency and also painful enough that it's worth your time. Because the worst part is that you might solve a problem that no one actually ends up caring about. But that's very general, I guess, to building any type of startup. What's really interesting about building an AI startup is that you want to figure out which part the AI can actually empower and enable. So that's the problem. After you identify the problem, just try to build a very quick prototype. I would say a lot of people either underestimate or overestimate what AI agents can do. Almost nobody has a balanced view, I think, and only the people who really get their hands dirty and actually build with it understand it the most. There are people who think AI can do everything, and there are people who think it's completely useless. Obviously, as with most situations, the truth is somewhere in the middle. So yeah, I agree that building some prototype and getting it to the market as soon as possible is one of the best things people can do. Because what I see with a lot of people is they stay in this idea phase forever—like they research, prepare, and think they have the world's greatest idea, but then, as you said, nobody wants to use it. **Yeah, exactly.** I often talk to people. When I say, "Oh, my idea is, let's say, an F-in model specific for my use case," which requires a huge amount of training data to begin with, instead of trying to spend months preparing training data, maybe just try out with a simple strategy. See what the default outcome from the large model is. This will speed up the idea to prototype process a lot faster as well. Yeah, there are solutions that would be perfect but would take like one or two years to create, right? Or solutions that would be like 80%, and you can just use, you know, CLA 3.5, Sonet, or GBD 40, and you can prove it that way. So I think, again, people are always aiming for that perfect thing, but maybe we need the next generation of models to make that happen. I think there are a lot of ideas that are possible, just not now. People can waste—maybe not waste, it depends if you consider it a waste—but they can spend a lot of time developing an idea that isn't ready yet. The classic example is Google Glass, right? It's like the AR glasses from, I think, 2012 or whatever. It was way ahead of its time, and now we see that Meta AI is obviously creating a much better product. AR glasses are going to be a thing, but Google was super early with that. I think a lot of people are going to be the same with AI agents, where they think they can automate something really complicated, especially in content creation, where the creativity part is really missing. I see a lot of possible startups there. I think, like, you know, I have thousands of hours in CH GPT and CL. I know the models can't do it. So yeah, I think people either underestimate or overestimate. Also, what's funny is that a lot of beginners want to build something that is AI-powered but could probably be solved with just raw code. That's also a funny phenomenon I noticed. **Yeah, exactly.** When you think about it, a lot of startup ideas literally can be achieved with spreadsheets in the old days, right? So instead of building your whole platform, you could just build like a spreadsheet automation and see that this actually works. **So, real quick, if you want me to help you grow your business, then click the first link in the description.** I will be choosing five people who make at least $2,000 a month, and I'll help them scale to $40,000 a month and beyond. I've already done it twice myself, so I'm certain I can help you do it too. However, this project is limited to five people only, so make sure to fill out the form today. It's the first link in the description. I also think with AI agents, what people don't realize is that reliability is by far the most important. The obvious example that everybody uses is plane tickets, right? People think it sounds good to have 99% reliability. "Oh, it's 99%!" But if you know every 100 times your AI agent booked a ticket to the wrong country or booked a hotel in a different state or country, you would not be happy. So in reality, we need like 99.9% reliability, if not more, in AI agents. For most use cases, that's simply not the case right now. People need to realize with their idea how quickly they can get to that 99.9%. Because if it's going to take you like two years in the AI space, that's like, you know, two decades or more. **Yeah, reliability is for sure key.** I agree. I actually think I kind of learned it the hard way for the past few months because we were trying to build a sales agent. Let's say, think about if a B2B, you want to outreach to customers. Instead of hiring a person to do that outreach, which takes a long time and training, why not have AI agents who can take a list of customers and research outreach, things like that, and also book meetings? One thing we realized is that use cases like that, exactly what you mentioned, require a really high level of accuracy because it's customer-facing. You don't want to mess things up. So those types of use cases can still work, but you basically need to find a specific segment of customers who have really high risk tolerance. They're okay with it being 99%, but they accept that. For this type of use case, you probably would need to find a very specific segment of customers who can go live with that. Otherwise, you guys just keep stuck in that iterating loop that's kind of forever going on. So setting up expectations correctly with those use cases is very important. On the other hand, what's probably more important is that you probably want to think about what a use case is actually okay to mess up for most customers. It doesn't require 99% accuracy. For example, if you look at internal automation processes, that's probably a bit easier. If you look at automating the whole process of, let's say, marketing—writing content, publishing content—but if you just do the content generation but still have a human in the loop as part of the workflow, then the risk tolerance becomes much higher. Sorry, yeah, the bar for the go-live standard is much lower, so that means you can go live easier as well. So this kind of accuracy really depends on—you really need to use accuracy almost as a benchmark to figure out what a use case is most suitable for your target audience. **If you want lifetime access to new Society, then make sure to follow me on Instagram.** All you have to do is like and comment on my three latest posts, and one of you is going to win free lifetime access. My Instagram is linked below. So I guess now is a good time to kind of introduce what your work at Relevance AI is like. What's your vision for the startup for the future, and what basically are you guys building? We are building the home of AI workforce. Imagine we basically realize that there are a lot of opportunities for businesses to automate their work. When you look at traditional automation platforms, there are platforms like D here or platforms like M.com or RPA platforms. Those platforms normally really focus on the integration and try to do a kind of point-to-point automation, which means if you have some kind of trigger or workflow, or some data from system A, and you want to trigger some workflow to system B, it's a very linear workflow. But with large language models and AI agents, what's really cool about it is that AI can start making a lot of fuzzy decisions, and it is able to do some sort of more agentic automation that wasn't possible before. This kind of platform is not good yet, so we are trying to build a platform that enables anyone to build kind of agentic workflows easily. People can build AI agents and then embed these AI agents as almost go-to random AI to build any sorts of AI agents backend and then connect to any sort of API they need. On the other hand, we also introduce a kind of chat UI for people to use and embed on the website directly. I think especially after CH GPT, people can understand the power of a chat UI, right? It's much easier to tell the agent what to do in text than to know all the settings or keyboard shortcuts or how to connect different integrations. So I definitely think that's good. I'm considering adding a chat interface to my app, even though productivity apps usually don't have it, just because people know how to interact with it. It kind of invites more people to use that AI agent. **So basically, you're trying to disrupt the Zapier world of automations where you still have to know what to do by making it easier for businesses to automate, right?** Yeah, exactly. When you build a workflow in traditional automation, you kind of need to know what the process is. You normally pick up those high-frequency, super high-frequency use cases and scenarios because those are the ones that make sense to justify the cost of deployment. But what this leaves out is a huge amount of long-tail use cases that are traditionally very hard to automate. Think about a use case like a meeting scheduling scenario. If you want to build an AI system or automation system that can book meetings for you, traditionally, it's actually very hard because people can respond in millions of different ways when you ask them, "Hey, what time do you want to meet?" They will say, "Hey, I'm in the office today but in the UK next week. How about Thursday?" That's really complicated to automate kind of long-tail use cases. But with large language models, this type of fuzzy decision is very easy to make once you train the agent properly. So this is the kind of use case and workflow we are focusing on. **And what's your role in the company specifically?** My background is in product design, so I'm doing a lot of product design and also was doing a lot of solution engineering work. What we realized at the beginning is that we are building this platform to enable anyone to build agents. But very quickly, we realized that it's so hard to actually build AI agents in production for enterprises. It requires so much upfront training and building. So what do we decide? Let's build a kind of flagship use case to showcase that this is actually going to work. That's what we started doing. Internally, we have a team to build and deploy AI agents for enterprise use cases as well. **Yeah, I think UI is one of the biggest bottlenecks for AI agents, right?** We all talk about reliability, but also what's preventing most businesses and people from having their agents is that it takes some skill, right? Some technical knowledge to build them. So I think we need the same thing that happened with CH GPT for LLMs. We need the same to happen with AI agents, where it's just so easy to build an agent that it doesn't make sense not to have one. The same way it happened with email as well, right? At the start, only the real programmers, the real OGs of the internet, had their own email, even before the internet. But after it became so easy, everybody had it. So I think UI is probably another bottleneck that's kind of preventing AI agents from becoming as popular as CH GPT, for example. **Yeah, totally.** We actually learned a few things as well. At the beginning, we kind of thought everyone would think about a chat UI, so you just chat with AI agents. But when we look into automation use cases, quite often what they do is not like chat. When I think about chat, it's more like a co-pilot use case. You build AI that can maybe retrieve information, and you talk to it. But when we look at enterprise automation, a lot of them is actually autopilot use cases, which means you have a workflow that you currently have a human to do, but you want to build AI to let it autonomously do it and automate the whole process. For this type of use case, the chat is probably not the main entry point for you. If you have an employee, you don't want to check every single task he was working on, right? So it's more like we started introducing different types of experiences for people to review the agent's tasks at different levels. For example, we need to design a very clear human-in-the-loop experience. When the agent needs help, how can you easily build a workflow inside your agentic work system so that when it's unsure, it can escalate to a human easily? After it's escalated, how can a human easily give instructions to the agent so that it knows what to do next? After the agent is given instructions and does the task, how can it actually learn about this interaction from humans so that next time it doesn't need to make the same mistake again? There are a lot of UIs around human-in-the-loop experiences. The second part is that, as we mentioned before, we realize when you have a fully autonomous agent running in production, you actually don't care about the chat UI too much at that point, at least from what we've observed. What you care about is, "Okay, how can I know how many tasks my agent has actually run for the past 24 hours?" So logs, basically logs and the review system. We actually introduced quite a smart way for people to let the agent label tasks by itself. If I'm reaching out to a prospect after research, I realize that it's a high fit versus low fit, the agent will be able to autonomously tag and label this task so that later you can come to the system and say, "Okay, among all the people we outreached, how many of them are high fit? How many of them are low fit? What's the email open rate? What's the reply rate?" So we started building out this kind of analytics system as well, which is quite interesting because when you think about it, it's actually a large language model system doing tasks and then labeling general reporting for the review autonomously, which is quite different from the traditional dashboard experience. So there are a few things we explore as well, both in human-in-the-loop experiences and also how we can enable humans to review the work that the agent has done. **Yeah, actually, you kind of gave me an idea to implement myself because I didn't have anything to kind of take care of.** For context for people, my AI agent is kind of sorting tasks, and I didn't have anything in place where if the confidence score was low, the human would review that. So I just got an idea: what if I just pop up a small warning icon or something like that? Let's say if the confidence score is below five out of ten or whatever, then the human can see that the agent wasn't certain where to put this task and probably review it. So yeah, I'm definitely going to add that. Thank you for that. **My next question is just for people.** A lot of people watching have their own businesses, right? They're small to medium-sized business owners, and they're wondering, "Okay, how should I think about implementing AI agents?" What do you think are some of the most obvious use cases that small and medium-sized companies should focus on? Do you mean like the use cases that they build for themselves as internal use cases or more...? Basically, what do you think are some of these things where they can get nearly 100% reliability with AI agents? **Yeah, so one thing that large language models are really, really good at is extracting insights and structured data from unstructured information.** There are a few use cases that we saw working really well and reliably. One is that companies have huge amounts of customer feedback data or meeting transcripts. It's probably a bit harder if you just give the agent your expectation is to generate a bunch of reports. That expectation, I would say, is probably a bit higher, and you will need a lot of fine-tuning to get it right 100%. But if you just give the agent a task, let's say, "This is a meeting transcript. Help me extract what's the action item from this meeting transcript and what are the pain points this customer talked about," that one is really, really good at, and the accuracy is to a level that you probably don't need to worry too much that it messes up things or extracts things wrong because just extraction is really good. From there, you can probably think about how to enable the sales process after the meeting is finished. Can you just extract information out from the meeting and then push that information to the CRM so that all that information is there, and the salesperson needs to focus on moving things? Or if you have a customer support ticketing system like Intercom, you can use this to automate the process. Whenever a ticket comes in, automatically extract the categorization: is this a budget report, a new feature request, and then triage and route it to the right people? There are a huge amount of use cases you can think about just about extracting information and structuring information from unstructured data, messy data. So that's kind of one big ability that's really reliably done by large language models. The second part, I think, is that you can... **Can you probably observe how people around you are using ChatGPT at the moment?** There are huge amounts of people just hacking things with it today. When you look at that, a lot of workflows are quite messy. My wife is working in the furniture business and is not technical at all, but she uses ChatGPT every single week to build blog posts. When you look at her workflow, it's like she will pump all the internal data out from their own CMS or CRM, go to ChatGPT, and then prompt it three or four times to get the output she wants. She might also go to an SEO website like Ahrefs to get keyword information and keyword ranking data to feed into ChatGPT so that it can start generating content based on all that information. So, a lot of repetitive actions, basically. **Yeah, exactly.** If you just observe how people are using that, you can probably build a micro SaaS fairly easily. It might not be a billion-dollar idea from the beginning, but I think it should be straightforward if you try to make, let's say, $10,000 or $50,000 in monthly revenue. I think that's probably doable if you're just looking at those use cases. **Yeah, I think there's going to be a surprising amount of companies that are in that range, right?** Maybe like low five figures, mid five figures. A lot of people watching would give everything to have a $50,000 per month AI startup. I think I don't know who said this—maybe it was Naval Ravikant—who predicted that there would be like a billion companies in the future where, thanks to technologies like AI agents, people will be able to start their own companies with zero employees. Or maybe you have AI employees like AI agents. **Yeah, I think it will absolutely be the case.** Let's say a year from now or two years from now, we're going to be paying even more for these AI subscriptions because we're going to be using one thing that saves us 30 minutes a week, another thing that optimizes our desktop a bit, organizes tabs, whatever. There are going to be so many different, as you said, $10,000 to $50,000 companies that are just super niche. They're not in a multi-billion dollar market, but they solve very niche problems that a certain avatar is going to be more than glad to pay for. **Exactly.** Especially with the recent AI coding trend, the entry point has become even easier. You are not just building an AI solution; you can use existing solutions to build a new kind of platform pretty easily. One thing I was experimenting with the other day is that, similar to the ability to extract structured information from unstructured data, when you look at this type of ability, the agent is actually very good at web scraping. It can look at HTML and figure out what data you care about. I remember going to platforms like Upwork, and if you search today, there are still hundreds of web scraping jobs available. It used to take quite a bit of time to build every single web scraper because every website is different. But a lot of people didn't realize that you can actually use large language models to build web agents that can literally scrape any website and get information out. There are public opportunities like that as well. You don't even need to provide a software service; you can create an agent that actually delivers the job and sell the work unit as well. I think this is one of the biggest untapped opportunities right now. For the next 6 to 12 months, people can make $1,000 here, $2,000 there on Upwork. There are so many things you can solve with either ChatGPT 3.5, Sonet, or GPT-4. There are so many projects where people just offer $700 to $1,500 that if you just put it into GPT-4 with one to three prompts, you would have it built. It's kind of crazy. **Yeah, exactly.** Also, the extraction part you mentioned could be very useful with emails. A lot of people, especially if you have a company, get a lot of low-quality emails. There are going to be AI agents that can set custom criteria, right? If you're looking for inbound leads, only certain clients have to meet specific criteria, like revenue or location. That is going to be for sure a thing. What do you think is the situation in the email department? To me, that's kind of obvious. Why hasn't that been revolutionized? It feels like emails are a bit behind still in terms of automation with AI agents. **Yeah, I actually think email is one use case that has been touched a lot.** Maybe not on the consumer side, but on the business side, it has been done quite a bit. For example, we saw a lot of VC companies building AI agents to automate their internal processes because they get a lot of inbound inquiries. When you think about it, the volume is huge, and there are so many mixed qualities of those emails that it didn't really make sense to justify the human cost before. But with AI agents, it starts making sense for them to look at millions of those messages and figure out which ones need to be handled. We have seen some workflows actually deployed in companies that look at incoming emails, categorize them based on different rules, and even trigger workflows. For instance, if it's a startup company, the agent can research the company and extract information like recent funding, team size, whether the product is live or not, what type of product it is, and what the revenue model is. You can actually get all that information from the company's website and then push it somewhere. There are a bunch of things happening like that already. **I think part of the reason, or at least what we saw at the beginning, was stopping the adoption.** If you want an agent to take over someone's personal email address that they have been using for years, there's a lot of pushback. They don't want to do that, especially if you want the agent to not just do data processing but also take actions. That part is really kind of scary for them. But there are mechanisms you can implement. For example, if you are building an outbound agent, you can create an email that can only handle emails that it sends out. If someone else sends an email to this inbox, it can ignore that. For those types of actions, you can create a more low-risk handling process. Instead of sending an email directly, it can draft that email in your inbox so that a human can step in for every single action. **So this kind of approach can help drive adoption.** But I definitely think email is something that has been on the tip of actually driving a lot of adoption. You mentioned the recent boom in AI coding, right? The last three to four months have been insane with new tools coming out and existing tools being massively improved. I think we're legitimately like 6 to 12 months away from people just typing one sentence and, in 30 seconds, having a fully deployed startup that can accept payments on the web. I think it's going to become so easy that literally all of us will be building custom software for the smallest of things. Right now, you can obviously still build custom software internally for stuff, but it has to meet a certain bar; otherwise, it's a distraction. **I think in a year, we're just going to have, "Oh, it would be cool if we had a Google Meet internal clone that has an AI agent inside with GPT voice that can answer questions." Boom! In five minutes, you have it built.** Do you agree with this? That it's going to be so easy to build an entire AI app, any app with AI, in about a year or two? **Yeah, I definitely think so.** Both Unb and others have been diving into AI coding, and we are starting to see this new market emerge. What's really cool about the AI coding trend is that the first generation of AI coding tools, like GitHub Copilot, was cool, but the target market was still programmers. It didn't really unlock new opportunities. However, with tools like Cursor and especially platforms like B. New, they can unlock this new market of people who never knew how to code. I actually talked to the founder of B. New the other day, and what they are trying to focus on is really targeting those people who are non-coders. This introduces a lot of new challenges. For example, people often have wrong expectations about what to tell AI. They give very vague answers, so they introduced a bunch of features to automatically improve the prompts for the user, even if they give vague ones. In one of my previous videos, I was exploring whether we could have a standard prompt for standard features like login or payment that I just need, but I don't care how it's implemented. There are things that, on one hand, I think the community will come up with standard AI coding prompts to make development easier. On the other hand, platforms like B. New will probably integrate directly with Supabase and programmatically set up the data table in your backend or automatically provide native integration with Stripe. You just click on "enable payment," and everything will be set up for you. I definitely imagine this will come in a year's time. **We already have early adopters starting to learn all these AI coding workflows and doing a whole bunch of things in a very time-consuming way, but I expect that we're getting much better.** What you describe with the prompts is basically what Vzer is doing with their UI. They are taking pre-built snippets that are proven to work and implementing them based on what the user wants. Maybe that is going to be the real answer, the unlock for B. New and Replicate Agent, where they try to understand what the user wants roughly and then take expert prompts or expert snippets of code and implement that. Otherwise, the LLM is going to be confused. It's very easy for beginners to point the LLM in the wrong direction because the LLM just generates the next token. It will gladly follow your bad instructions and lead you down a path, and then you might be shaking your fist like, "Oh, you know, AI models suck!" when, in fact, your prompt was completely terrible, and you confused the AI, and it didn't even know what to do. **Yeah, I think that's probably among beginners the biggest challenge: they don't even know how bad their prompts are.** **Exactly.** And actually, by the way, I think that's probably one good startup idea there as well. Currently, we have platforms like Cursor's directory, but to be honest, all the content it has just follows the Cursor rules. From my experience, that part wasn't really that helpful. What would be really helpful is those modular prompts that you can just take and put into your current codebase with some prompts so that the AI actually understands your project structure. I think that's a pretty good idea if someone were to do it. I would personally use it a lot. **So you mean like inserting it as a comment in the code instead of just following Cursor rules?** **Yeah, exactly.** I found that the rules you're putting into Cursor actually didn't really follow that strictly. I need to remind it, yeah, I need to remind it. **Yeah, exactly.** I found that to actually get it to work properly, my best practice is for every single feature, I actually have a very specific markdown file. If I'm implementing, let's say, user authentication, I will have a prompt that I use quite often inside this markdown file. I would explain, "Okay, this is the service you should use; this is the file structure that I expect," and this is the current project structure. The second and third sections are actually very important because quite often, the cursor doesn't really understand the project structure at the moment. Then it just creates a file in the wrong place with the wrong dependencies. To actually get Cursor to follow things, I will normally create those specific feature markdown files and then give them to it. **Exactly.** That's probably the best way I found to actually tame it. If that works, what is needed is what are all the markdown files for specific features? I observe myself actually keeping a repository of those prompts for user authentication, payments, backend setup, and so on. I imagine mine is not the best since I'm not a professional front-end developer, but there are all the other different use cases and scenarios that could be pretty standardized. **So I do something slightly different.** I still use the Cursor rules, but I have different processes. I have a process for implementing new features, a process for fixing errors, and then I have to still remind it in the actual prompt to follow the error-fixing process or the building process. When I remind it, it does it right. So I have different processes for different types of work I do within Cursor, but still, when I remind it, it follows the process. For me, this is what I found to be the most time-efficient, I guess. **Yeah, those are the general rules that should be followed.** I think Cursor rules are actually good for those general principles you should follow for different scenarios, but on top of that, you can probably combine that with feature-specific prompts so that it can do the feature with the best practice workflow, resulting in fewer errors. **So for people who are watching this, most of them are not senior developers, right?** How would you approach that? Would you consult with someone about how to build a good login feature or a good payment integration and then take that, put it into markdown, and upload it? **Yeah, I actually have a very specific workflow that I don't see many other people doing.** Basically, what I do is a few things. One is that Cursor, at default, quite often doesn't do the planning that well. The second one is that especially if you're using some new package, it's almost guaranteed it will have errors because it doesn't have the knowledge backing it. If you just go to Cursor and give it instructions about what you want to do, it will often fail. Instead, what I will do is maybe I can quickly share my screen to show you as well. **Of course!** So this is normally what I do when I start a project. I actually want to generate a very... Oh, sorry, not this one. Give me one second. **Okay, here you go.** This is kind of normally the markdown file I would generate. It's pretty much like if you're part manager, part designer, you're pretty familiar with project requirement docs. It basically includes the whole table of contents about what's the overview of the product, what core functionalities are required, what the file structure is, and additional requirements. I will break down every single feature, what the requirements are for every single feature. In this part, I also have very detailed instructions about which package you should use, what kind of data points you should get from the API endpoint, and then list out the final file structure you should work towards so it understands the dependencies. In the end, I will include very specific documentation and code examples to implement some feature that uses the new package. This is kind of like the final docs that I will try to get ready before I implement it. **But I guess the question workflow I think will be interesting is how do we actually get to the doc?** This might feel pretty daunting and a lot of work to actually write this doc. What I normally do is that I will try to start with a draft doc instead of having this whole thing. I normally just have a few sections. I would have a section called... Let me check. I think I have a template I can copy-paste over. **It looks something like this.** So I have a project overview, core functionality, current file structure, and additional requirements. I normally just write this part, but not very detailed, to be honest. It's some kind of like a simple doc. So let me paste in an example. **I had just a side note when you mentioned that people don't realize the model doesn't have access to the internet and uses outdated versions.** It's so surprising to me how many people still don't understand this. It's almost every day I see somebody asking ChatGPT something without telling it to browse the web to do something, or ChatGPT, which doesn't have internet access. People need to realize that if the LLM doesn't have internet access and you're asking for something recent, it's going to hallucinate an answer that seems legit but is not real. This is a super common mistake I see with people. **Yeah, totally.** It's actually quite hard. Even though sometimes you give the URL and doc, it still gets things wrong. It's crazy. Sometimes the training data is so strong that it values it so highly. **Exactly.** That's why I actually always follow this process of doing some pre-work. If I paste in, I normally try to write down this. Basically, I found that with where it is at the moment with large language models, it has all sorts of potential paths to get errors. What I do is peel off those risks and uncertainties by doing this planning early on. I might just write things like project overview, and then I will write down kind of like core functionalities instructions. This might feel a bit daunting, but when you look deep into it, it's really just a list of requirements about what the core functionalities needed are. But these two, I think, are pretty easy to do. The third part is one I guess I will start spending a bit more time on. I want to include the working code example for the agent or for Cursor about how to use certain packages so it doesn't hallucinate and it doesn't make mistakes later. What I normally do is, let's say in this case, I want to use Snowflake as a package. I will go there and then add a doc which is connected to the doc that I want to use. Then I will just ask it to, let's say, "Help me build this simple TypeScript script to do this job." Then I will run it. It will try its best to read the doc and get information, but as you mentioned, it often fails. When I observe that it fails, I will personally read the doc and just copy-paste the most important part in. Through this process, you normally start creating some kind of testing script that I can run and debug this very modular feature until I get the result I want. After I get the result I want, then I can copy this thing into the doc and say, "Here is a code example of how to use..." **Uh, snow, uh, snow wrap to fetch RIT data.** So, I’m pasting this code example that I know is working for my testing so that, um, Cursor doesn’t need to—Cursor is less likely to make a mistake later. So, I basically repeat this process. Just a side note for people watching this: this is a really good practice to kind of test out every small feature or every change you do. Because if you, like, go, you know, multiple hours without doing any testing and then something doesn’t work, it’s like a nightmare to figure out what is causing that issue. So, like, the more testing you can do in general, the better. **Yeah, exactly.** So, basically, I will repeat this process a few times until I get the very modular code snippet working. And when I’m doing this, the benefit is that I actually don’t need to worry about, okay, whether how they can interact with other files. We didn’t mess up the things, like you mentioned, which will very likely happen if you just go code directly. So, I’ll do this, and then I will also kind of put in the file structure as well. So, normally, this is like after I set up the project. I found often C of since it didn’t have an understanding about the file structure, which is very surprising because I think they should be able to know that pretty easily. I think that’s a feature you should definitely add, but it also seems like it knows, right? Because when you type the pr and you, like, control enter it, it looks like the graphic kind of tells you like it knows the structure, right? But sometimes it feels like it doesn’t. **Yeah, exactly.** It definitely feels like it doesn’t. That’s why at the moment, I normally what I do is that I will use this one package called Tree. So, Tree will be able to generate the, let’s say, the file structure for you. So, if you are in a Node.js project, I would do `tree -L 2`, which means it will go to label deep, and then `-I` to ignore certain folders or files I just don’t care about. And then this will kind of show you the file structure. This is a bit like Wick, but normally what it would generate is like an actually proper project structure for you, so I can copy-paste it over as part of the kind of file structure here. **Yeah, I mean, it just becomes more valuable as your project grows, right?** It’s like with small projects, if you have like five or seven files, it’s not a big deal. But once you have like backend, frontend folders, and like folders within that, it can become confusing. **Yeah, exactly.** So, I would normally, like, let’s say, here this one is probably bad, but let me see if I can find a better one. So, normally for project structure, it will look something like this after you run it. It gives you like a very detailed project structure so that it understands the dependency much better in this way. And in the end, I will include some kind of additional requirements. So, additional requirements are like based on the type of project you’re creating. I found it often can make similar mistakes. And this is one that I have a collection of prompts I’m adding here for different projects. Like if it’s an iOS app, it has a list of things I want to add. If it’s a web app, then this is also a list of things I want to add as well. So, if this is a web app, I would just paste in the things that I have here, like things like where do you put the components, which Next.js version we should use, where should we create new pages, things like that. **So, this normally is like the first draft,** but I often found from my experience if I just give it directly to the Cursor, it’s not that great as well. So, that’s where the 0.1 comes in in my workflow. So, I will copy-paste this, let’s say the basic one, and then I will go to like 0.1 version. **Let me try to find the ones that I used last time.** We still need to see how good the actual full 0.1 is because 0.1 preview is not even the full version. **Yeah, exactly.** But normally, I will go here, pasting that in, and then ask a few things. Like, firstly, I will ask it to figure out the file structure because I basically say, "This is the feature I needed, and this is the current file structure. Help me design architect how this, how different files should exist in my project based on the feature request." Then it will kind of generate the file structure. And after it gets the file structure, then I ask it, "Okay, now great! Now I’ll try to generate a very detailed product requirement doc that any engineer can just take a look at and then start picking up without any ambiguities." So, with that, I found 0.1 is really, really good. **So, sorry, yeah, should probably switch to 0.1 preview and later the full 0.1.** So, with that one, this is normally how I get the final instruction like this, which is very, very detailed and very clear. **But don’t you find like sometimes 0.1 inserts just unnecessary details and that complicates the project a lot?** **Yes, sometimes it would do.** That’s why I, when I ask it to generate the file structure, I would put in some specific instruction like, "Try to create as few pages as possible," so that it has a bit more kind of the—it’s less likely to make errors on those file structures. **Yeah, that’s good.** **Yeah, but yeah, this is kind of my current workflow.** You can see this huge amount of upfront planning, but that’s kind of a current hack of getting through those different errors and limitations of large models. **Yeah, just one caveat to that I would put for beginners watching this:** you actually want to make sure you don’t, you know, get stuck in the planning phase. Because, like, you know, you might spend, like, you, Jason, are compared to the average viewer, you’re like a genius programmer, right? So, you might spend a few hours building that, but you’re going to get to the building phase. A lot of people are like, "Okay, I still need to do more research. I still need to watch more videos. I still need to ask Perplexity." And then they’re like, "Oh, Perplexity gave me a different answer than ChatGPT. Like, you know, which framework should I use?" So, one big caveat I had for people watching this: don’t get stuck in the preparation phase forever, right? Don’t skip it. For sure, do some prep. You know you need some clarity about what you’re building, but get to the building part because if you don’t, you’re never going to make it. **Yeah, totally.** Like, you should build—like, this person looks long, but part of that is actually I want to build as fast as possible because I want to ask to build small building blocks. So, I know especially parts that are more complicated, you want to test to understand, does this part actually work? Because otherwise, the rest actually didn’t even matter. **So, yeah, totally agree.** **So, I want to ask a selfish question:** would you recommend me building fully the backend, like the AI functionality first, and then try to connect the frontend? I mean, I already have like a basic design with Vzer, but I don’t have it connected with the backend, or would you recommend me build both at the same time? **Yeah, so my personal workflow is actually I try to use Cursor to build the whole functionality first.** Okay? And then I basically—so, you know when you go to Cursor, it will actually help you build a whole functionality per whole page. Even if the page looks not as good, I just don’t care at the beginning. I just want to build whole functionalities and later, because if you’re building a web app, it basically will create a bunch of pages for you. **Right.** This time, actually, I start using V0, so I will just copy-paste page by page and ask, "Okay, now try to make this page look a lot better and keep the style the same." So, that’s kind of my workflow because I basically just want to separate Cursor to just focus on functionalities because it is really good at it, and then V0 do the front end. **But if I do the other way, which I know actually is pretty popular kind of workflow, my challenge is that for building more complicated features, I found it actually makes it a bit difficult because in Vzer, I believe it only creates like one single page.** **Yeah.** But often, you would need the whole project. **Yeah, that’s what I found.** Like, I started with Vzer, then it was like 600 lines of code, including some of the functionality I was like, had to slowly remove it, put it into the backend, and like, you know, update stuff. It was like, yeah, maybe it’s good practice to stick to like less than 200 lines, and then probably your approach is definitely better. Just have Cursor build everything, forget about like looking nice, just focus on the actual functionalities that it works. And once you’re happy with how the app works, then you can start polishing the UI and, you know, making it easier to use. So, I’m definitely going to do that because right now I have like a solid UI and a solid backend and a complete disconnect. I’m wondering, like, should I—because I want to keep building the agent, right? I want to keep building the Python backend; that’s what I like to do. But then still, I need to connect the frontend; otherwise, it’s not an app. So, I’m like wondering whether I should do it, and like, I think you just answered it, so I appreciate that. **Yeah, nice.** **So, any final advice for people who are new to AI or new to AI agents?** I think my probably specific for agents one is that I found is sometimes it’s easy to get into the feeling of like shiny to kind of experience. You saw a new framework launch every day, and you want to like, "Okay, which one should I use?" But what I found is really useful is actually just build an agent. Don’t use any framework; build from scratch. **Yes!** And then you actually understand it’s actually not that scary. All those frameworks, they pack things together in all sorts of planning that they think is useful, but maybe not. So, just build an extremely basic function-calling agent by yourself by just calling the OpenAI API. You will get so much better understanding about all those new frameworks and which one will actually work for your use case. **So that’s probably my kind of one suggestion for people who are building agents.** Man, I couldn’t agree more! Like, I started with frameworks, and now I never use them. I just do direct API calls to OpenAI, Anthropic. It just gives you complete control, and, you know, I think you can never go back. **But anyways, Jason, I appreciate you taking the time.** I think it was a super great episode. I’ve learned a lot, and I’m sure the viewers have as well. I’m going to link your channel and your community below the video so people can check it out. And yeah, thank you for taking the time, man! **Awesome! Thanks a lot. Have a great day, man.** **Bye! Have a good day! Bye-bye!**
Залогинтесь, что бы оставить свой комментарий