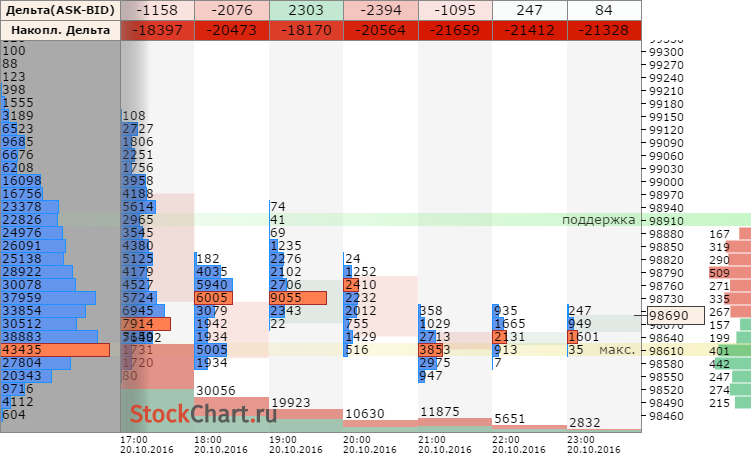
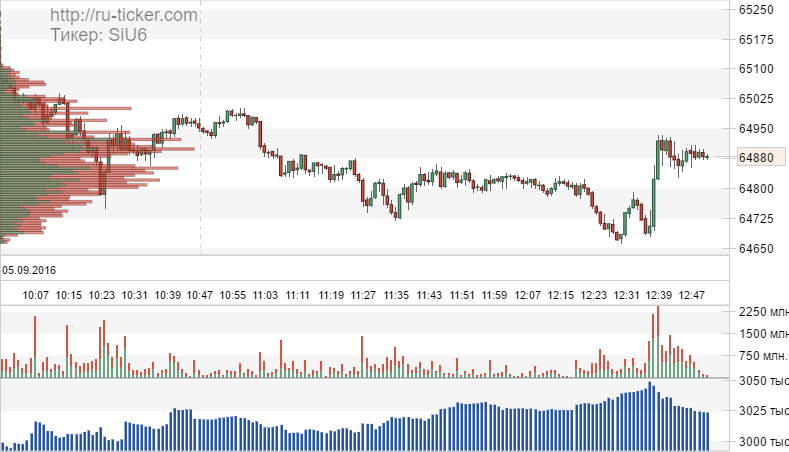
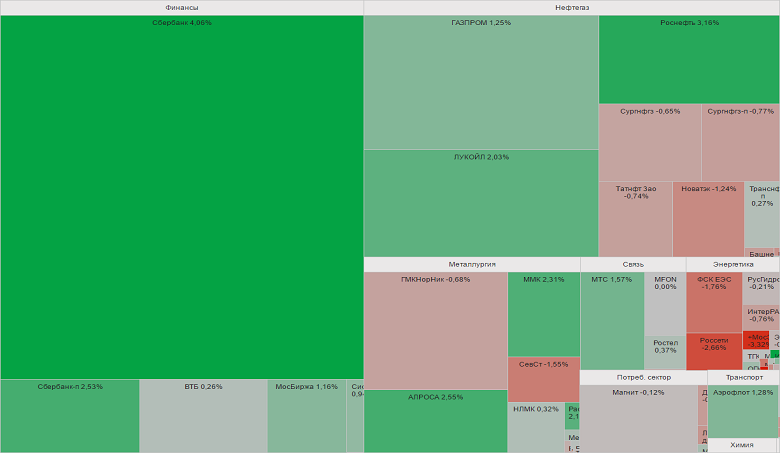
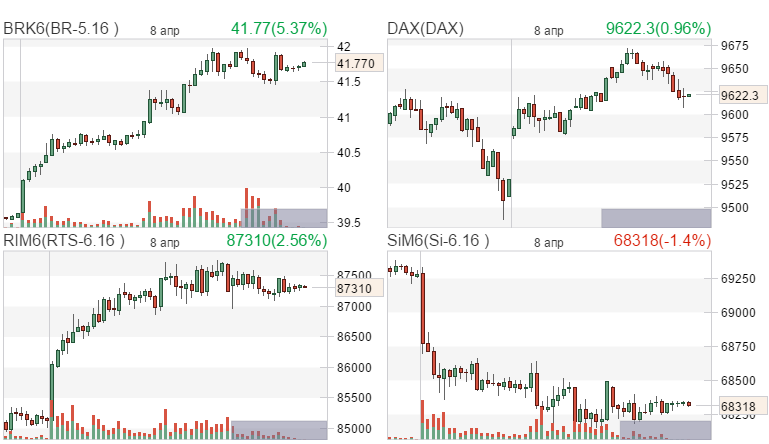
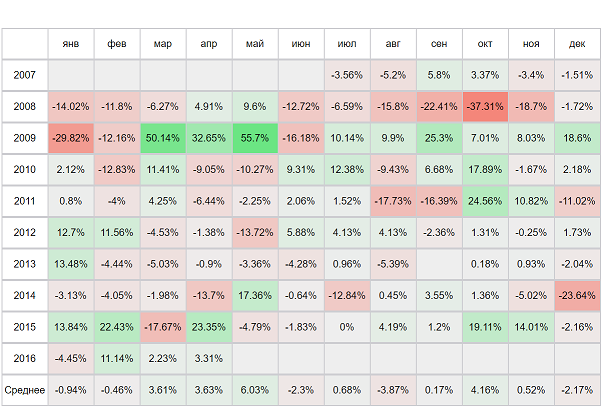
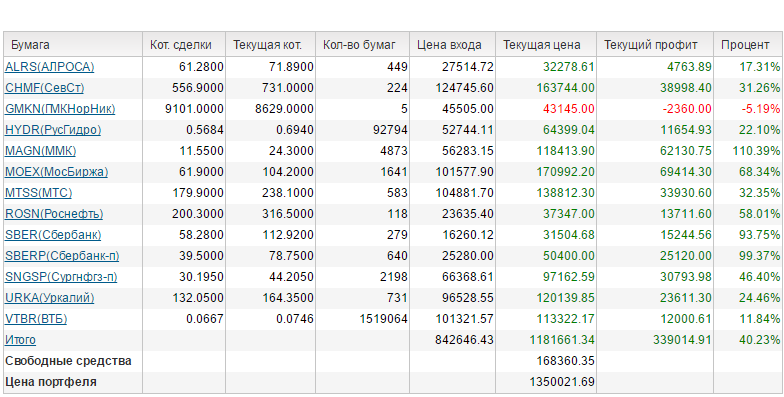
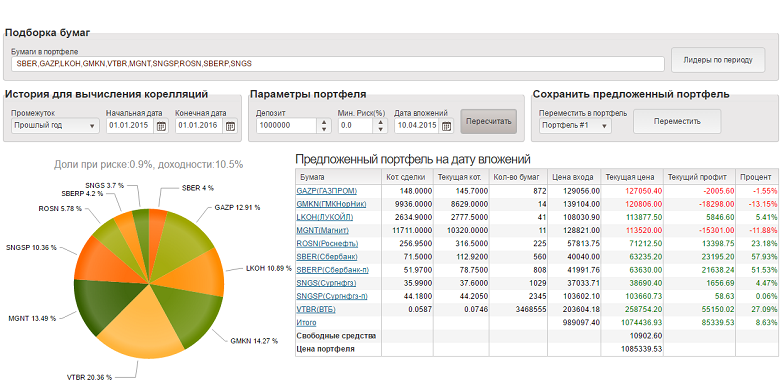
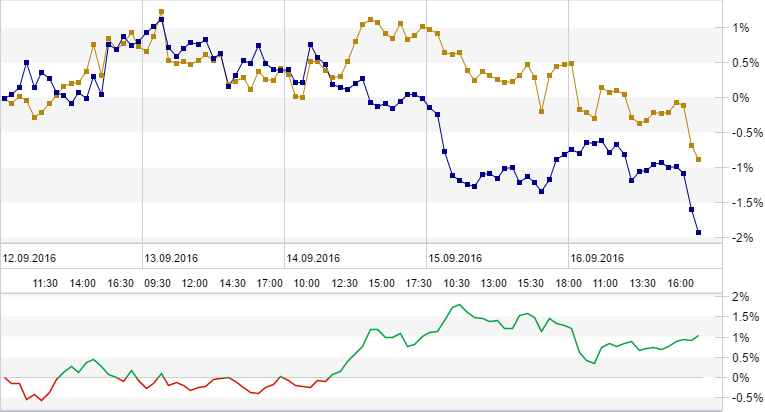
Copyright © StockChart.ru developers team, 2011 - 2023. Сервис предоставляет широкий набор инструментов для анализа отечественного и зарубежных биржевых рынков. Вы должны иметь биржевой аккаунт для работы с сайтом. По вопросам работы сайта пишите support@ru-ticker.com