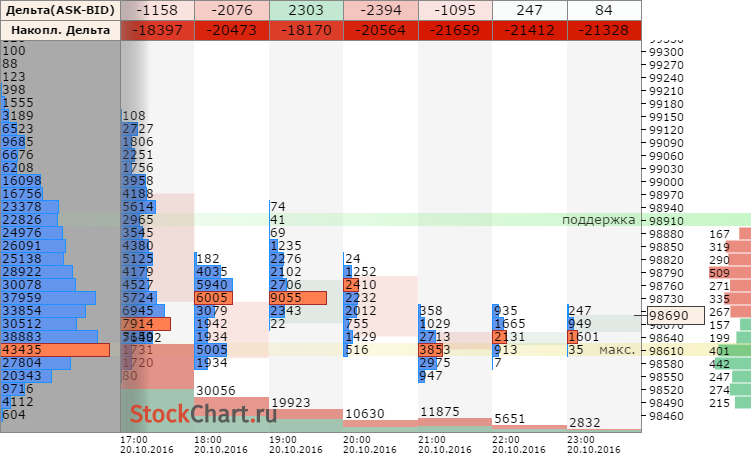
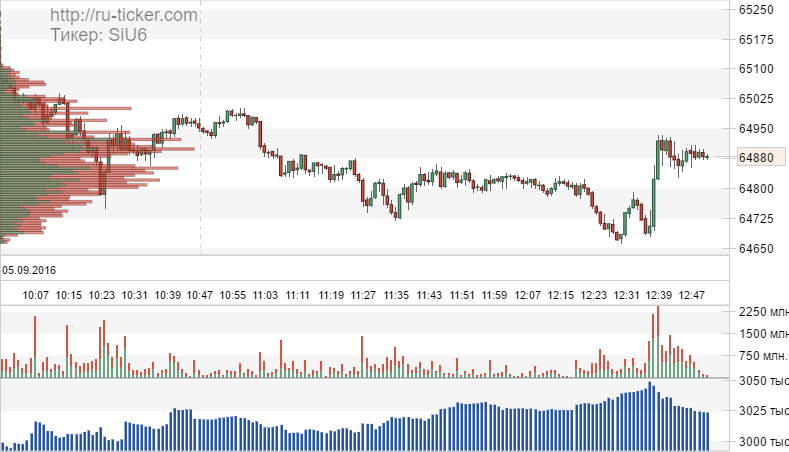
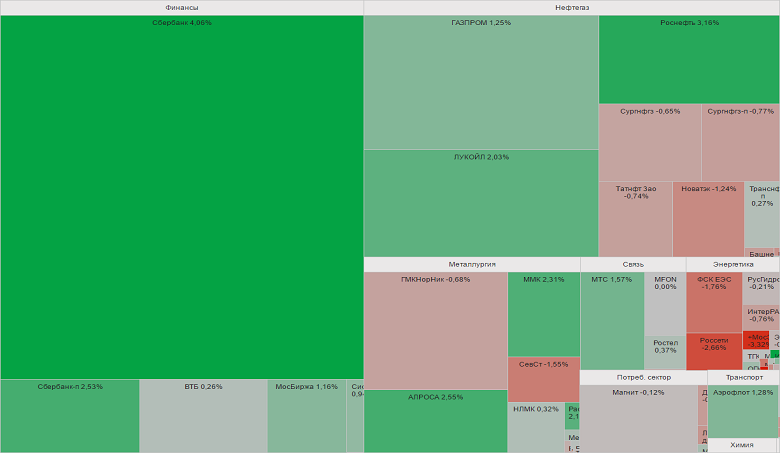
 | | | |||||||||||
|
|
||||||||||||
| | | |||||||||||||||
|
|
||||||||||||||||



Техническая поддержка
ONLINE
| | | |||||||||||||||||
|
|
||||||||||||||||||
Data Engineering Zoomcamp 2025 - Streaming - with Zach Wilson
ruticker 05.03.2025 11:07:47 Recognized text from YouScriptor channel DataTalksClub ⬛
Recognized from a YouTube video by YouScriptor.com, For more details, follow the link Data Engineering Zoomcamp 2025 - Streaming - with Zach Wilson
# Introduction Hey everyone! I'm Zach Wilson. Today, I'm going to be teaching y'all about **Kafka** and **Flink**. It should be a pretty interesting lab today; I've got a lot of interesting stuff rolling together here, and I'm really excited to be teaching this class. I know that the Zoom Camp stuff is one of the most impactful ways to give back to the data engineering community, and yeah, it's going to be awesome! I'm really happy to be here. Thanks for being here; it's amazing to have you as one of the instructors. # Overview I took a short look at the content that Zach prepared; it's amazing! So, you are all going to love it. We will put everything in the module information on streaming, so later in a few days, you'll find everything you need there. I guess that's all I wanted to say, so now, Zach, the floor is yours. # Setting Up Awesome! Let's share my screen here. Today, I'm going to be working with **Docker Compose**—a lot of Docker stuff today, a lot of Flink, and a lot of PostgreSQL. One of the things I want to start this off with is that we're going to have four components. There are actually four machines that we're going to be spinning up with Docker to start with in today's lecture and lab. If you go to this Docker Compose file, you'll see that we will be using **Red Panda**. We are going to be using the **Flink Job Manager**, the **Flink Task Manager**, and last but not least, we have **PostgreSQL** as a nice way to get all of our data in one spot. We can look at it, query it, and understand what's going on. Let's go ahead and start that. I'm just going to do a `docker-compose down` real quick to make sure my state is the same as your state. You can say `docker-compose up` here; this is going to create all of these machines. You'll see, if you look at Docker, they'll all be in here now: we have our Red Panda, PostgreSQL, Flink, Flink Job Manager, and Flink Task Manager. To make sure that things are actually running right, you want to go to `localhost:8081`, and you should see an **Apache Flink dashboard** here that has everything for your task slots. You should see a "1" here to make sure the task manager is actually running, and there are probably no running jobs or completed jobs quite yet. That's something we're going to be working on here in a second. # Setting Up PostgreSQL We need to get a couple more things set up before we get into Flink. If we go back to the Docker Compose, we want to get PostgreSQL set up. You're going to need to use some sort of DB tool. In the homework, I'm recommending **DBeaver**. In this lab today, I'm going to be using **DataGrip**. When you do this, you're going to need to add a few comments. Sorry for those who have no idea what DataGrip is. In the first module, we used **pgAdmin** for that, so it's a similar tool. PGAdmin, DBeaver, and DataGrip are just ways to run SQL queries on a database, right? So, when you make a connection, the host is going to be `localhost`, port `5432`, username is `postgres`, password is `postgres`, and the database is `postgres`. Just `postgres` all the way down. If you're using a JDBC connector, you can kind of use this kind of URL as well, depending on how you're connecting. This should connect us up to PostgreSQL, and we should have the ability to run a query. You'll know it's working if you can query the information schema. Great! So this is working really well. We need to do this because we're trying to set up a landing zone for our data from Kafka. This is a very common pattern where you have data that comes from Kafka, gets read in real-time, and then gets dumped somewhere else—whether that be a data lake technology like **Iceberg** or a transactional database like PostgreSQL. # Creating the Processed Events Table Now, we want to create our **processed events** table. One second, this is the wrong one; I have way too many tabs open. We want to go and create the processed events table, which will be here in the homework. We want to run this query here called `processed_events` and just run this DDL. This is going to give us our data table for Flink. You should end up seeing it in here; it should actually show up. There it is! Okay, cool! Now we have our processed events table with the two columns that we are looking for. Amazing! This is going to get us set up for being able to take data from Kafka to Flink to PostgreSQL. That's going to be the other big piece of this puzzle. Now we've worked with both PostgreSQL and the Flink Job Manager. Obviously, we're going to need to interact with all of these containers to get this to work because streaming has so many different moving pieces to it. # Adding Data to Red Panda The next thing we're going to want to look at is **Red Panda**. We want to end up adding data to Red Panda. We have a couple of different Python files in here that you can work with. We're going to be using this one called `producer.py`, and this is going to add just a bunch of test data—just some kind of junk data that we're going to be using. Remember that with Kafka, when you are loading data into Kafka, the big one is it has some sort of **server bootstrap** server. This is going to be where Kafka accepts the event. Kafka also has a **topic**, and you can think of topics as kind of like a table. They are like the table of Kafka where you have the ability to accept data and put it into a spot. When a producer connects to Kafka, that's what we're going to be doing here with this Kafka producer. We are going to be connecting to our server on our Kafka server on `localhost:9092`. This is Kafka; Red Panda simulates Kafka, so we're able to do all this locally. Most of the time, in an actual data engineering environment, this is something that would be spun up in the cloud, probably with a service like **Confluent** or something else. Another thing here is when you send an event to Kafka, it has to be serialized in some way. You can send objects to Kafka, but it needs to be serialized into a format that can be written to disk. In this case, we're doing just a very basic **JSON serializer**. The reason why we need to do this is that some data types between Python and Kafka and JSON have to have an interchange format between systems. The way that Python represents data and the way that JSON represents data and the way that another language like JavaScript or TypeScript represents data—all have different data types and different ways of representing things. We need to use a standard interchange format in order to push events onto Kafka so that we can essentially read them from any other language. The most common option to do this is going to be JSON. With that being said, there are other options out there like **Thrift** and **Protobuf** that you could definitely look into. JSON is great in the fact that it's very easy to set up, but it's also not great in that it takes up the most space. This is where if you use something like Thrift or Protobuf, that would be a great thing to look into if you want to take these labs to the next level. That's another way that you can change this value serializer. # Sending Data to Kafka Let's go ahead and actually send some data to Kafka. That's probably something that y'all are interested in. We have all this running. I'm just going to open a new window. In this case, we're just going to say: ```bash python3 src/producers/producer.py ``` This is just going to dump hundreds and hundreds of data—just dumping all sorts of data to Kafka. You'll notice when I ran that, we had a response from Red Panda. You can see it here where it's like, "Hey, we're actually creating a new segment of data for this test topic." You should be able to see this in the logs, assuming that you're not running Docker in detached mode. We know that the data got accepted by Red Panda, and that's going to allow us to move forward with the next step in this process, which is going to be going back over to our jobs. We have a couple of jobs here that we're going to be working with. We're going to be mostly working with this `start_job.py`. The two Flink jobs that we're going to work with today are `start_job.py` and `aggregation_job.py`. These are going to be the two files that will really show how all of these things work together. Let's see if that actually finished. I think it did. There's the other tab. Okay, cool! Did we send? Huh, we just sent an integer and a timestamp—nothing fancy here. We have two different types of jobs here that we're working with. We're starting with something very straightforward and simple just to really get people aware of how all of these things work because we're going to be getting into watermarking and a lot of other things here as well. We should have a thousand events in the Kafka queue that are waiting to be processed. # Connecting to Kafka with Flink So how do you do that? How do you actually connect to Kafka and connect to all of these things with Flink? We're using PyFlink here, and this allows us to process all of the data using Python. With Flink, there are two concepts that you really want to be thinking about: you have a concept called a **source** and a concept called a **sink**. A source is something that you read from, and a sink is a place that you dump to. When we want to read from Kafka, what we're going to be doing is connecting, and you have to put a couple of different parameters when you're creating a table here in Flink. You'll notice that there are several important parameters: 1. **Connector**: This can be Kafka, an RSS feed, a REST API, a WebSocket—Flink can literally connect to everything. 2. **Bootstrap Servers**: This is just going to be our Red Panda address. If you have multiple, it's common to have redundant bootstrap servers when you're working in the cloud. 3. **Topic**: This is the table that we're reading from in Kafka. 4. **Offsets**: You can put `earliest`, `latest`, or a specific timestamp to control what data you want to read. 5. **Format**: You have to specify what format you are working with, such as JSON or CSV. This is our source, and this is how we're going to set up a source. Interestingly enough, the name of this table doesn't matter that much because this table only exists within Flink when it's running. # Questions and Answers **Quick question:** So, first of all, just to understand, Kafka is the communication channel where we send messages. There is a thing that sends messages to Kafka, right? The messages are stored in Kafka—in our case, it's Red Panda—but it could be Kafka or something else that implements the Kafka interface. So we send the messages there, and then there are things that can read from this communication channel, like **ksql** and **Flink**, right? **Zach:** Yes, exactly! Flink can read from there. It looks at the stream of data and checks what has already been processed and what is new. This is where the offsets come in. **Question:** So when we start Flink for the first time, it creates this table. But if something happens and our job dies, and we start it again, does it necessarily process the entire thing again, or how does it work? **Zach:** That's a great question! When you kick off the job, if you started off with `earliest offset`, it will read everything in Kafka from the beginning. However, if it restarts, it will use a feature called **checkpointing**. This takes a snapshot of the state of the job every 10 seconds, so it knows how far it has read when it fails. When you restart the job, it won't read from the earliest offset; it will read from the last checkpoint. This is very important for resilience. If you use `latest`, you might skip data when you redeploy. These have interesting trade-offs, and I encourage everyone to read up on the differences between **Lambda** and **Kappa architecture**. Streaming can be a little brittle, and bouncing back from failure can be more difficult. Does that answer your question? **Question:** Yes, it does! So when Flink starts for the first time, it creates this table, but when it fails and starts again, it keeps the checkpoint somewhere in memory or on disk, right? **Zach:** Exactly! It realizes the table exists, and it uses the checkpoint to know where to start processing. It gets complicated, especially if it fails in the middle of a window. It will serialize the open windows to disk, which is another piece of checkpointing. You want to balance resilience and efficiency, especially at scale. With these examples, it's hard to illustrate, but that is definitely a piece of this for sure. Now, let's go down to the actual job to understand what's going on! # Log Processing with Flink So, our main method here is **log processing**. When Flink starts, it sets up an **execution environment**. This environment allows Flink to know what's going on and where the state is. We are enabling **checkpointing**, as we just discussed. One interesting aspect is that Flink actually has a **batch mode**. When we set up our environment settings, you can change this to batch mode, which allows Flink to process a chunk of data and then stop, treating it more like a standard batch process. In contrast, in **streaming mode**, the job will continuously listen for more data. Next, we have our **table environment**, where we create tables and define different sources and sinks. This is where Flink starts to understand these components. You'll notice we have an **Event Source** created. ### Watermarking For this source, we have a **watermark**. Since this first job is just a pass-through, pulling data off Kafka and immediately writing it to PostgreSQL, watermarking doesn't do much here. Watermarking is significant when you're working with windows. You can think of a window in Flink as similar to a **GROUP BY** statement in SQL. However, it's more complicated because some of the data you're grouping on might not exist yet or could arrive out of order. The main purpose of watermarking is to specify the tolerance for out-of-order events. In this case, we set it to **15 seconds**. If any events are out of order within that time frame, Flink will wait an extra 15 seconds to ensure it captures any incoming events that might be out of order. Watermarking can be based on different criteria: data timestamps or Kafka timestamps. These can differ due to network issues. For example, if you click a button on your phone while in a tunnel, the event might not be sent until you leave the tunnel and reconnect to the internet. ### Creating the PostgreSQL Sink Now, let's create our PostgreSQL sink. This function allows us to create connectors. In this case, we use the **JDBC** connector, and our PostgreSQL table is named `processed_events`, which must match the name we used in our SQL queries. This setup allows Flink to run **INSERT** queries into PostgreSQL in real-time. We then call `wait`, which essentially waits for new data to come in. Our source table is Kafka, and our sink is PostgreSQL. ### Running the Job Now, how do we get this job to run? In the code, we have a **Makefile**. You can use either `make` or `Docker Compose`. I'll use Docker Compose for this. The `make job` command will run a Docker Compose function that calls the job manager to run the Python file. Since Flink is a Java library, we need to specify that we're using Python by adding the `--py` flag. Let's go ahead and run our Docker Compose function. You should see that the job manager picks it up, and the job is submitted with a job ID. If we check the job status, we should see it running. ### Observing Real-Time Data This job is a pass-through, so many of the metrics will remain at zero because Flink isn't holding onto any data; it's just processing it. To verify that the job is running, we can query PostgreSQL, and we should see data being inserted. Let's add more events to Kafka using our producer. Each time we run the count query, we should see the number of rows increasing in real-time, demonstrating that Flink is continuously listening and processing data. ### Handling Job Failures Now, let's explore what happens if we kill the job. If we restart it, we should see the checkpointing mechanism in action. However, if the job is completely removed from the job manager, we may encounter duplicates. This is because the checkpointing is specific to the job instance, and killing it removes that context. To avoid duplicates, it's better to use a timestamp for offsets instead of `earliest`, which pulls in everything. If we cancel the job and restart it, we can recover from failures more effectively. ### Changing Offset Strategy Let's change the offset strategy to `latest`. When we run the job again, it will only process new data that arrives after the job starts. This approach is useful for minimizing duplicates but may lead to missing some data. In big tech environments, it's common to use the `latest` strategy and then process any missing data in batch mode to fill in the gaps. This highlights the trade-offs between completeness and latency. ### Aggregation Job Now, let's look at the aggregation job. We need to create another table in PostgreSQL to store aggregated data. This table will have columns for `event_hour` and `num_hits`. The source for this job is similar to the previous one, but it includes aggregation logic. We can use **GROUP BY** to aggregate data over time windows. Flink allows for parallel processing based on the key of the data, which is essential for handling large datasets efficiently. ### Conclusion In summary, this overview of Flink demonstrates how to set up a basic streaming job, handle real-time data processing, manage failures, and perform aggregations. The flexibility of Flink allows for various configurations and strategies, making it a powerful tool for real-time data processing. # Understanding Lateness in Flink Um, uh, example, right? So what you're talking about is there's two types of lateness, right? The first type of lateness is, you know, I call it like, you know, when someone's like one minute late to Zoom, and you're like, "Okay, they're not even late because they're just there." There's like an acceptable amount of lateness, and that is going to be—you can think of the watermark as that amount of lateness that you're like, "Okay, it's fine; you arrived on time." But if you're talking about something that's late beyond the watermark, there is, um, Flink has that—let me, uh, let me—there's like a **allowed lateness** in Flink, so you can set that as well. There is a—so allowed lateness is going to be, yeah, it has another value that you can set in Flink, which is like what is considered dramatically too late, right? So there's actually two lateness values here. So like in your case, maybe we do set that allowed lateness value to 10 minutes or whatever, right? Then what happens in that case is when you're out of the tunnel and your event gets sent, and these are one-minute windows, Flink will actually go back and find that old window and create a new window with your data, right? But that also adds another record, and so on your sync side, you need a way to deduplicate the windows to correct for that. That is something that you need to do. Like if you use allowed lateness, that's definitely one of those trade-offs—like how much allowed lateness do you want to do? And that's another thing with allowed lateness: Flink has to hold on to all of those windows on disk. So after Flink does its group by, and then say the one minute completes, and then 15 seconds happen after that, then that window is now closed, and that window can be passed to the sink. Then if you create data that triggers a window that is closed, it will generate a new window and pass that to the sink only if that timestamp is within the threshold of allowed lateness. The default for allowed lateness is zero, but there are jobs that do that. You can also process this data separately; you can do side outputs for the late data so it goes somewhere else. You can manage the lateness in maybe a batch process later on, or there are a lot of different ways that you can handle this. But I like the side output; it's a really solid way to go for really late data, which will create an interval that is the more correct interval—the actual correct count of the events—but it just arrived later because you were in a tunnel. That would be, I guess, that would be my very caveat answer to that question. # Summary of Lateness Handling So let me try to summarize what you said and at least also make sure I understood what you said. So like with default settings, the event would be just discarded, yeah, because allowed lateness is zero, right? So the way it works is events are coming, and we process them. Flink processes them, and let's say our window is one minute. So we accumulate data over one minute, we process them, let's say we do a group by minute and count. So we are interested in the number of events in this window. Once we have the number, we know, "Okay, this is the minute." I don't know, right now it's 17:55, so for this minute, we had 10 events, right? And then we just, at the end of the interval, we just flash it to whatever sync we have—let's say it's a PostgreSQL database—then we just insert a new record, right? So this is what the default behavior is. If we allow late lateness, then we would need to somehow go back and update this final aggregated value, right? Because we will have set a new window, right? Yes, it will read. So what Flink will do if you put allowed lateness here is everything that's within that window of whatever allowed lateness is—like say you do a 10-minute window—all of the windows within that time frame will be serialized in Flink as well. It will read whatever the window was before it was closed by the watermark, and then it will add your event to the window and do the new count and the new aggregation. But it does send a brand new event and a brand new window to your sinks. So, yeah, you need to have some logic to combine these two windows, right? The aggregation would be just to overwrite whatever is there because the latest one is almost the correct state, right? But sometimes it would be, I don't know, doing a sum or whatever, depending on what exactly we do in our case. A very common thing that they do in PostgreSQL is there's a thing called **ON CONFLICT UPDATE**, right? Where you just pull in the new count because it's like you have a primary key on this guy, and then we could put on conflict update so that we just update the count to what its actual correct value is. That's a very common way to handle this situation, but the right way to handle this does depend on the use case, though. # Running the Aggregation Job Yeah, you're totally right about that. Amazing! Thank you! Awesome! So let's go ahead and actually run this job. I think that that's probably something that y'all are interested in doing. So, let me go ahead and change this from `start_job` to `aggregation_job`, and this will go ahead and kick that off. Oh, I input field list. Okay, there's a—what second? There's something fishy here. So we have our event timestamp. Oh, I have a—oh, because I put window timestamp, and I think it's event watermark. Yeah, this is—should be event watermark. That's the issue. Query schema: event test data. Oh, sync schema. Oh, we need to put the test data column in there too because we are actually grouping on that. So this needs test data integer, yeah, and then we have our—yeah, we have the column here as well. So, oh, we got to drop this guy, though. Okay, let me go ahead and do that. It says test data. Perfect! Okay, now that will give us what we want. So now, just run one more time here. Flink's pretty good; it tells you what the problem is, right? So it can analyze the query. You can see here I'm like, "Oh, I'm missing that column," right? And it's pretty good. The actual—it gives you very similar stuff to Spark in that way. So now, like one of the things I want to show here, though, is if we go back to `8081`, we should see this. There we go! So one of the things that's really cool now is we actually have—like you'll see, remember when we first did that pass-through example that I was talking about? Now we are actually holding on to data, right? And you'll see we actually get performance metrics here now of how much data we're receiving and where it's coming from, and we have our records, and it's all kind of there, right? So this is working pretty well now, but we should be able to see some data here. Like, okay, so I think it hasn't—that doesn't make sense. Is that—uh, second? We have the log aggregation, and this is going to be from path execute insert aggregated table. Okay, that should be there. So we have our aggregated tables here; it has our test data num hits. Okay, that might take a minute. Oh, it's because I think it's latest. Is it actually reading in? No? Okay, no, that should work then. Like, is that—like for some reason not actually—oh, there's probably a failure in the insert or something. Let's go into that. Can we go to the exceptions? Let's go running jobs, events, exceptions. Exception? Okay, that's not—is this one? It says that it's just records sent, records received, and then does this have—watermarks are only if event time is used. There should be—but this does have—maybe, like you said, we just need to wait. I mean, it should only take like one minute, though, right? And like, yeah, because like it would be this. Okay, there's something here that is a little bit off. I think it's because we have event watermark, event timestamp for event watermark as event watermark. That should be—this should be our watermark because that—like, I think that that—it's—I know that the group here is a little off. I think that's what it is. Like, is it this? Because this is our tumble window. It is reading the tumble window for sure. That's super weird that it's like actually—because we have our timeline. We do have it. Okay, checkpoints are actually okay. What's actually—okay, the one way to test this is like, let's load some data here just to see if that causes it to—because, okay, it definitely picked up that next data, and then this should potentially dump out another row. Like, is there—there's nothing else in here that I'm doing differently, right? That's super weird. Okay, because this should be grouping here, like on—okay, so we're creating our window, and then we are grouping on that window. But there should be like a watermark thing here. One second, let me actually throw on like a thousand records again because this thing should turn red. It should turn red whenever we dump a bunch of data. Like, see, that's like—okay, so it is picking up the records here. Like, maybe it's the thing that we need to wait on. I don't think so. I think it's not actually picking it up. Usually, this stuff's a little bit faster. Like, it's—because we are only doing a 15-second watermark, right? And so, one second, I have another example of this. I was like very close. I have the—one second, how did I do it here? One second, there's a watermark for four—water time stamp. Okay, we got the timestamp there, and then this is window timestamp. Call, call, call. Okay, that is—it is—it is reading in. Okay, what the hell? Um, okay, yeah, it's definitely not loading in the data. That's like—it should be picking up on the watermark there, though. That's why this is essentially not sending data anywhere. That's what's literally going on. Like, CU, there's just no exceptions, though. It's very interesting. Okay, let me think here. Like, okay, like these windows, I know that there's a small thing here. There's some very small thing on this watermark that is not—like it's not pulling it in or something like that. It's not—like grouping on the right thing. I swear I had this working before. Yeah, maybe do fix it later, and then, yeah, this will be fixed. This will definitely be fixed by the time we publish all this code. But anyways, I wanted to go over here with—because we have a—like with the homework, we're going to be working more with taxi data, and there's going to be a lot more columns that you're going to be working with. # Types of Windows in Flink So there are many types of windows that you can work with, right? So this is the most basic type of window, right? You have a **tumbling window**, which is very simple. It's very like, "Okay, we're going to cut up our job into one-minute segments, and that's just how it is." Then you have a **sliding window**, which is a little bit different because when you think of like a one-minute window, a lot of people think of like the first minute of the hour. But there's actually another one-minute window because you could think of like 30 seconds of one minute to 30 seconds of another minute. Like that's also one minute, but it's a different one minute, and it's like half of one minute and half of another one minute. So you can have a sliding window, right? That's like—oh, I think that's what I'm missing. I think it's, uh, yeah, I think I'm missing this key by. I honestly think that that's what it is from because then you have **key by**. Window, so in this case, that's literally what's missing here. So it's key by, and then call, and then this is test data. I'm pretty sure that should—because now this is a keyed stream. I want to see if that works, actually. See if that like actually fixes our problem. But anyways, back to like sliding windows versus tumbling windows. Well, we'll let that run, but like so tumbling windows are very straightforward. They just cut it up into very obvious things. If you live in a batch world, a tumbling window is very similar to like the batch world. Then you have sliding windows, which are very good for optimizing. So if you want to figure out like your peak, right? Your peak user count or your peak growth or your peak whatever, you can use these overlapping windows to find the moment in time where you have the highest or lowest values. This is good for min-maxing sort of things. And then a **session window** is very good for just grouping user behavior together so that you can analyze things in a group, and you can analyze a set of events as a session. Just like what it talks about here, sessionization is super powerful. Those are essentially the three types of windows. I want to see real quick if that actually—if me missing that key by was the actual—oh no, that was—oh, the current table has no column name. Key by key is it keyed by? Did I like go back here? No, it says it's do key by. That's right. Okay, um, from path table. Key by column test data source tape. Okay, so I want to just try this one more time, and if this doesn't work, I'm giving up. This—okay, so key by does not work because columns available event watermark because that's super weird that like should work. Is it after the window? Is that what it is? Is it like—because, okay, so that goes, and then that goes, and then that—interesting. Anyways, I will... a way that rabbit is used for like a request-response model, right? So if you have a situation where you need to send a message and get a response back, rabbit is a much better fit for that. But if you're looking for something that can handle a massive amount of data and scale horizontally, Kafka is the way to go. So it really depends on your use case. If you need strong delivery guarantees and you're working with a smaller scale, rabbit might be the better choice. If you're dealing with high throughput and need to process a lot of events in real-time, Kafka is likely the better option. To learn more about these tools, I recommend checking out the official documentation for each technology. There are also many online courses and tutorials that cover the differences between these messaging systems and when to use each one. Additionally, community forums and discussions can provide insights based on real-world experiences. In summary, the choice between Kafka and alternatives like RabbitMQ should be based on your specific requirements, such as scalability, delivery guarantees, and the nature of your data processing needs. In like, if you have an application that's listening to stuff, Kafka's used a lot more in offline jobs. But Rabbit is great, especially if you have a use case where you want the data to show up in a UI and do an event. It has the big connections of all this stuff. Also, the big thing is you pick Rabbit if you know the volume is never going to be very big, right? By "very big," I mean tens or hundreds of gigabytes at least. Rabbit can still handle a lot too, right? Just like with PostgreSQL, which can handle terabytes. Sometimes we over-engineer things. Rabbit also has this ability to route stuff, so it's more than just a broker. It can push things in different directions. If you want data to be sent and published to certain places, you don't need Flink; Rabbit can do that itself too. It's like a signal sender as well, whereas Kafka just goes in one direction. It's just a giant fire hose pointed in one direction, whereas Rabbit's more like a traffic router that can stop, do this, move this, and so on. It has a lot more complexity to it in that way. Would you say then maybe RabbitMQ is for usual backend engineers and software engineers, while data engineers are more likely to work with Kafka rather than messaging queues? Yeah, exactly! I'd say Rabbit is a lot more likely to be for application engineers, for sure. Okay, well, that's it! We took a bit more time, but thanks for taking the time to answer the questions and prepare the materials and share them with us. What we are going to do right now is publish this video, and we will push all the materials in the Module 6 part of our data engineering course. I hope my laptop is back to life because right now it's just blinking. I do not see you, Zach, right now. Every time I teach Flink, I always have weird stuff like that happening, and you're not even teaching, but it's always when I'm teaching Flink, so your laptop has the problem! Okay, so I keep my fingers crossed that when I turn it off and on again, it works like it usually does. So yeah, I guess that's it. I'll just need to figure out how exactly I stop the stream. If I just power off, that should stop the stream, I guess. Yeah, but I have to figure this out. So thanks, Zach, a lot! Pleasure! Thanks everyone for joining us today. Keep an eye on the announcements; we will announce the homework soon. Right now, you're still working on Module 5 Spark, so have fun! Awesome! Thank you so much! This has been amazing. Have a nice day! Bye everyone! See you! Yeah, I'm trying to turn off my computer right now.
Залогинтесь, что бы оставить свой комментарий