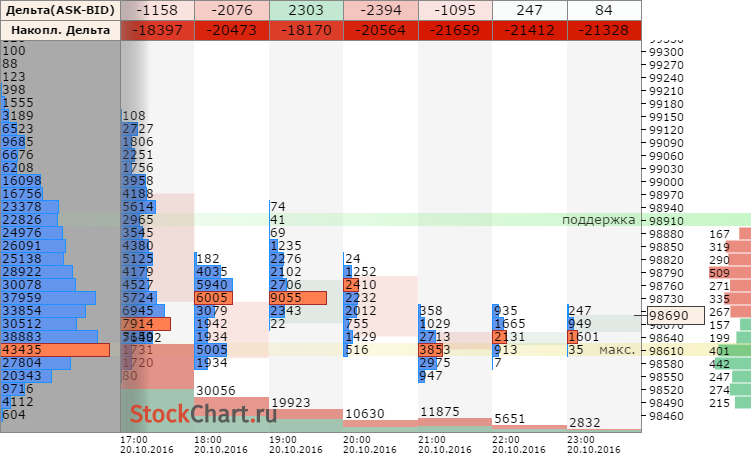
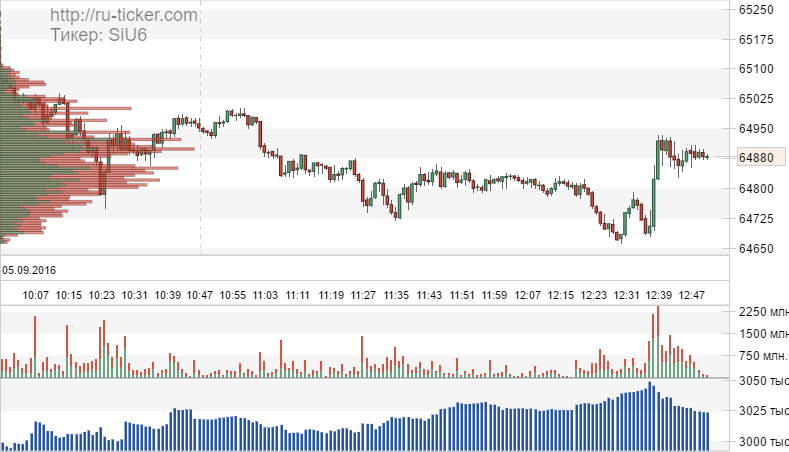
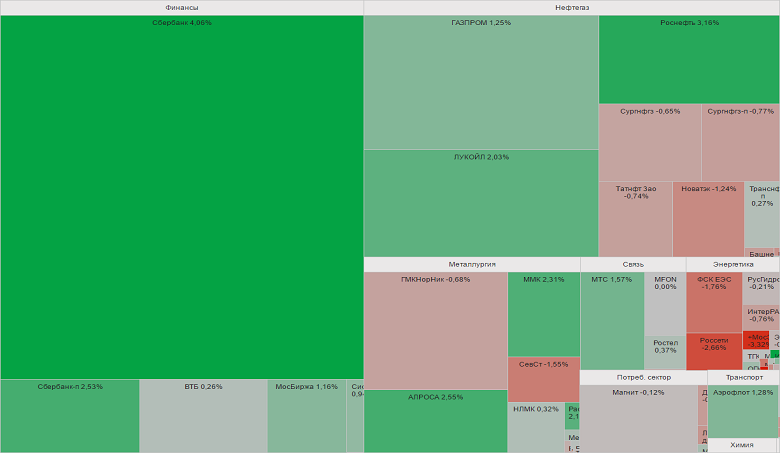
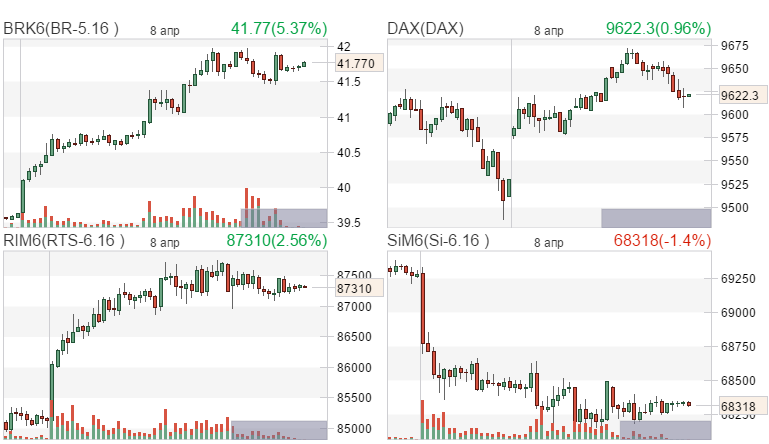
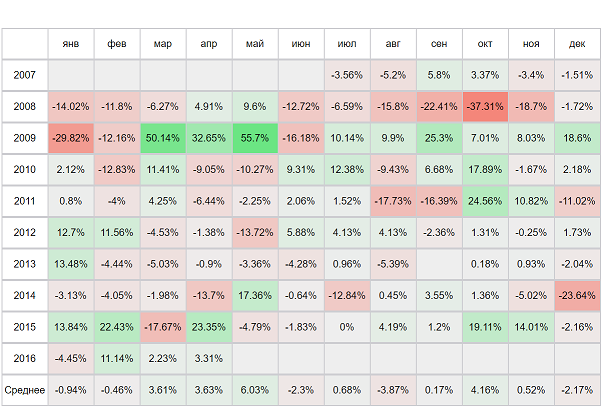
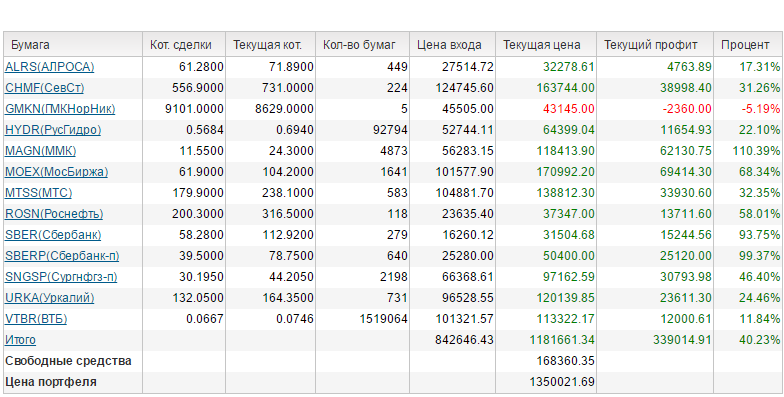
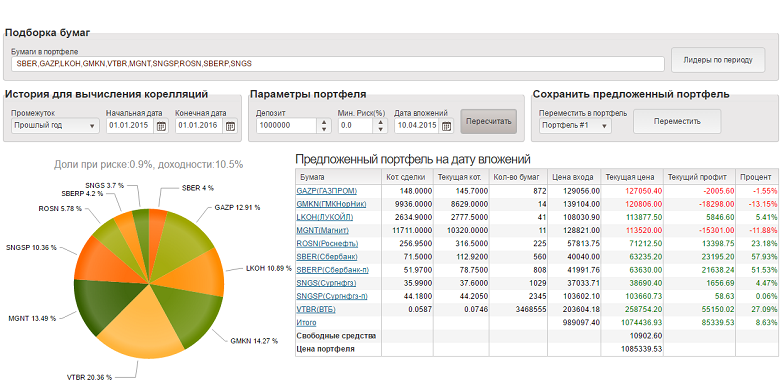
 | | | |||||||||||
|
|
||||||||||||
| | | |||||||||||||||
|
|
||||||||||||||||



Техническая поддержка
ONLINE
| | | |||||||||||||||||
|
|
||||||||||||||||||
Deep Dive into LLMs like ChatGPT
ruticker 04.03.2025 15:24:51 Recognized text from YouScriptor channel Andrej Karpathy
Recognized from a YouTube video by YouScriptor.com, For more details, follow the link Deep Dive into LLMs like ChatGPT
# Introduction to Large Language Models Hi everyone! So, I've wanted to make this video for a while. It is a comprehensive but general audience introduction to large language models like ChatGPT. What I'm hoping to achieve in this video is to give you kind of mental models for thinking through what this tool is. It is obviously magical and amazing in some respects; it's really good at some things, not very good at other things, and there's also a lot of sharp edges to be aware of. ## What is Behind This Text Box? You can put anything in there and press enter, but what should we be putting there? What are these words generated back? How does this work, and what are you talking to exactly? So, I'm hoping to get at all those topics in this video. We're going to go through the entire pipeline of how this stuff is built, but I'm going to keep everything sort of accessible to a general audience. ### Building ChatGPT Let's take a look at how you build something like ChatGPT. There are multiple stages arranged sequentially. The first stage is called the **pre-training stage**, and the first step of the pre-training stage is to download and process the internet. To get a sense of what this roughly looks like, I recommend looking at this URL here. This company called Hugging Face collected, created, and curated a dataset called **Fine Web**, and they go into a lot of detail in this blog post on how they constructed the Fine Web dataset. All of the major LLM providers like OpenAI, Anthropic, and Google will have some equivalent internally of something like the Fine Web dataset. ### Goals of the Pre-training Stage Roughly, what are we trying to achieve here? We're trying to get a ton of text from the internet from publicly available sources. We want a huge quantity of very high-quality documents and a large diversity of documents because we want to have a lot of knowledge inside these models. Achieving this is quite complicated, and as you can see here, it takes multiple stages to do well. For now, I'd like to note that, for example, the Fine Web dataset, which is fairly representative of what you would see in a production-grade application, actually ends up being only about **44 terabytes** of disk space. You can get a USB stick for like a terabyte very easily, or I think this could fit on a single hard drive almost today. So, this is not a huge amount of data at the end of the day, even though the internet is very large. We're working with text and filtering it aggressively, so we end up with about **44 terabytes** in this example. ### Data Sources Let's take a look at what some of this data looks like and what some of these stages are. The starting point for a lot of these efforts, and something that contributes most of the data by the end of it, is data from **Common Crawl**. Common Crawl is an organization that has been basically scouring the internet since 2007. As of 2024, for example, Common Crawl has indexed **2.7 billion web pages**. They have all these crawlers going around the internet, starting with a few seed web pages, following all the links, and indexing all the information. You end up with a ton of data from the internet over time. ### Data Processing Stages This Common Crawl data is quite raw and is filtered in many different ways. Here they document a little bit of the kind of processing that happens in these stages. 1. **URL Filtering**: This refers to block lists of URLs or domains that you don't want to get data from. Usually, this includes things like malware websites, spam websites, marketing websites, racist websites, adult sites, and so on. A ton of different types of websites are eliminated at this stage because we don't want them in our dataset. 2. **Text Extraction**: All these web pages are saved in raw HTML by these crawlers. We want just the text of these web pages, not the navigation and other elements. A lot of filtering and processing goes into adequately filtering for just the good content of these web pages. 3. **Language Filtering**: For example, Fine Web filters using a language classifier to guess what language every single web page is in. They only keep web pages that have more than 65% of English, as an example. This is a design decision that different companies can take for themselves regarding what fraction of all different types of languages to include in their dataset. 4. **PII Removal**: This is the removal of personally identifiable information, such as addresses and Social Security numbers. You would try to detect and filter out those kinds of web pages from the dataset. There are a lot of stages here, and I won't go into full detail, but it is a fairly extensive part of the pre-processing, and you end up with, for example, the Fine Web dataset. ### Examples of Final Text When you click in on it, you can see some examples of what this actually ends up looking like. Anyone can download this on the Hugging Face webpage. Here are some examples of the final text that ends up in the training set: - An article about tornadoes in 2012. - Did you know you have two little yellow adrenal glands in your body? So, this is some kind of odd medical article. Just think of these as basically web pages on the internet filtered just for the text in various ways. Now we have a ton of text—**40 terabytes** of it—and that is the starting point for the next step of this stage. ### Tokenization Process Now, I wanted to give you an intuitive sense of where we are right now. I took the first 200 web pages and concatenated all that text. This is what we end up with: just raw text, raw internet text. There’s a ton of it even in these 200 web pages. Now, before we plug text into neural networks, we have to decide how we're going to represent this text and how we're going to feed it in. The way our technology works for these neural networks is that they expect a one-dimensional sequence of symbols and want a finite set of symbols that are possible. ### Encoding Text So, we have to decide what the symbols are and represent our data as a one-dimensional sequence of those symbols. This sequence starts here and goes here, and then it comes here, etc. This is a one-dimensional sequence of text. If I do what's called **UTF-8 encoding** on this text, I can get the raw bits that correspond to this text in the computer. It turns out that for example, this very first bar here is the first eight bits. This sequence length is actually going to be a finite and precious resource in our neural network. We don't want extremely long sequences of just two symbols; instead, we want more symbols and shorter sequences. ### Byte Pair Encoding One naive way of compressing or decreasing the length of our sequence is to consider some group of consecutive bits, for example, eight bits, and group them into a single byte. There are only 256 possible combinations of how these bits could be on or off, so we can represent this sequence into a sequence of bytes instead. In production for state-of-the-art language models, you actually want to go even beyond this. You want to continue to shrink the length of the sequence because, again, it is a precious resource in return for more symbols in your vocabulary. This is done by running what's called the **Byte Pair Encoding** algorithm. ### Tokenization in Practice Now, let's take a look at how GPT-4 performs tokenization, converting from text to tokens and from tokens back to text. One website I like to use to explore these token representations is called **Tick Tokenizer**. Here, you can input text and see the tokenization of that text. For example, "hello world" turns out to be exactly two tokens: the token "hello" and the token "space world." If I join these two, I get a different tokenization. You can play with this and see what happens. ### Neural Network Training Now we get to the fun part, which is the neural network training. This is where a lot of the heavy lifting happens computationally. We want to model the statistical relationships of how these tokens follow each other in the sequence. We take windows of tokens from this data fairly randomly. The window's length can range anywhere between zero tokens all the way up to some maximum size that we decide on. For example, in practice, you could see a token window of say **8,000 tokens**. ### Input and Output of the Neural Network In this example, I'm going to take the first four tokens. These tokens are the context that feeds into a neural network. The output is a prediction for what comes next. Because our vocabulary has **100,277** possible tokens, the neural network will output exactly that many numbers, corresponding to the probability of that token coming next in the sequence. In the beginning, this neural network is randomly initialized, so these probabilities are also going to be kind of random. We know what comes next, and that's the label. We have a way of tuning the neural network so that the correct answer has a slightly higher probability. ### Adjusting the Neural Network If I do an update to the neural network now, the next time I feed this particular sequence of four tokens into the neural network, it will be slightly adjusted. This process happens not just for this token but for all tokens in the entire dataset. In practice, we sample little windows and at every single one of these tokens, we want to adjust our neural network so that the probability of that token becomes slightly higher. This is the process of training the neural network. ### Internals of Neural Networks Now, let's briefly get into the internals of these neural networks. As I mentioned, we have these inputs that are sequences of tokens. These inputs are mixed up in a giant mathematical expression together with the parameters or weights of these neural networks. In practice, these modern neural networks will have billions of parameters. In the beginning, these parameters are completely randomly set. Through the process of iteratively updating the network, the setting of these parameters gets adjusted so that the outputs of our neural network become consistent with the patterns seen in our training set. ### Conclusion I encourage you to explore more about these neural networks and their architectures. This is just a brief overview, but I hope it gives you a better understanding of how large language models like ChatGPT are built and function. Thank you for watching! # Understanding Token Sequences and Neural Networks Token sequences flow through the neural network until the output, which consists of the logits and softmax predictions for what comes next—specifically, which token comes next. There’s a sequence of transformations, and all these intermediate values produced inside this mathematical expression are predicting what comes next. ## Token Embedding As an example, these tokens are embedded into a distributed representation, meaning every possible token has a vector that represents it inside the neural network. First, we embed the tokens, and then those values flow through the network. These are all very simple mathematical expressions individually, including layer norms, matrix multiplications, and softmax functions. ### Attention Block Here, we have the attention block of the transformer, and information flows through into the multi-layer perceptron block. All these numbers represent the intermediate values of the expression. You can think of these as the firing rates of synthetic neurons, but it's important to note that these are much simpler than biological neurons. Biological neurons are complex dynamical processes with memory, while these expressions are stateless and fixed mathematical functions from input to output. ## Inference Stage Now, let’s cover the inference stage, where we generate new data from the model. We want to see what kind of patterns the model has internalized in its parameters. To generate from the model, we start with some tokens that act as a prefix. For example, if we start with the token "91," we feed it into the network, which gives us a probability vector. ### Sampling Tokens From this probability distribution, we can sample a token based on the probabilities. The tokens with higher probabilities are more likely to be sampled. For instance, let’s say token "860" comes next. This token is relatively likely, but it’s not the only possible token. We can continue this process, appending tokens and asking for the next likely token, sampling each time. ### Stochastic Nature of Models Keep in mind that these systems are stochastic. We might not reproduce the exact sequence from the training data; instead, we generate remixes of the data. At every step, we can flip and get a slightly different token, leading to token streams that are statistically similar to the training data but not identical. ## Training and Inference Process In most scenarios, downloading the internet and tokenizing it is a pre-processing step done once. After that, we train multiple networks with different settings and arrangements. Once we have a trained model with a specific set of parameters, we can perform inference to generate data. ### Example: GPT-2 Let’s look at a concrete example: OpenAI's GPT-2. GPT stands for Generatively Pre-trained Transformer, and GPT-2 was published in 2019. It was a transformer neural network with 1.6 billion parameters and a maximum context length of 1,024 tokens. It was trained on approximately 100 billion tokens, which is relatively small by modern standards. ### Training Costs The cost of training GPT-2 in 2019 was estimated to be around $40,000. Today, you can train similar models for significantly less, around $600, due to improvements in data quality and computational efficiency. ## Training Process Overview When training a model like GPT-2, every line in the training log represents one update to the model. Each update improves the prediction for 1 million tokens in the training set. The key metric to watch is the loss, which indicates how well the neural network is performing. A lower loss means better predictions. ### Computational Requirements Training these models requires substantial computational resources. For example, I’m using an 8x H100 node, which consists of eight GPUs. These GPUs are ideal for training neural networks due to their parallel processing capabilities. ## Data Centers and GPU Demand The demand for GPUs has driven significant investment in data centers. Companies like Nvidia have seen their stock prices soar due to the increasing need for GPUs to train language models. The more GPUs you have, the faster you can process data and improve your models. ## Base Model Releases Once a model is trained, it can be released as a base model. A base model is essentially a token simulator, generating text based on the patterns it learned during training. However, base models are not directly useful for tasks like question-answering without further refinement. ### Releasing a Model To release a model, you need two things: the Python code that describes the model's operations and the parameters, which are the specific settings for the model. For example, GPT-2 was released with 1.5 billion parameters, which are just a list of numbers representing the model's learned weights. In summary, understanding the flow of information through token sequences, the training process, and the computational requirements is crucial for grasping how models like GPT-2 and GPT-4 operate. # Introduction to Llama 3 Release now! GPT-2 was released, but that's actually a fairly old model. As I mentioned, the model we're going to turn to is called **Llama 3**, and that's the one I would like to show you next. ## Overview of Llama 3 So, GPT-2 again was **1.6 billion parameters** trained on **100 billion tokens**. Llama 3 is a much bigger and more modern model. It is released and trained by Meta, and it is a **45 billion parameter model** trained on **15 trillion tokens** in very much the same way—just much, much bigger. Meta has also made a release of Llama 3, and that was part of this paper, which goes into a lot of detail. The biggest base model that they released is the **Llama 3.1 405 billion parameter model**. This is the base model, and in addition to the base model, they also released the **instruct model**. The instruct model means that this is an assistant you can ask questions, and it will give you answers. ## Interacting with the Base Model For now, let's just look at this base model, this token simulator, and let's play with it. My favorite place to interact with the base models is a company called **Hyperbolic**, which is serving the base model of the **405B Llama 3.1**. When you go to the website, make sure that in the models, you are using **Llama 3.1 405 billion base**. Set the max tokens to **128** to avoid wasting compute. ### Testing the Model Now, fundamentally, what's going to happen here is identical to what happens during inference for us. This is just going to continue the token sequence of whatever prefix you're going to give it. I want to first show you that this model here is not yet an assistant. For example, if I ask, "What is 2 plus 2?" it's not going to tell you, "Oh, it's four." Instead, it will just tokenize the question, and those tokens act as a prefix. The model will get the probability for the next token, functioning as a glorified autocomplete based on the statistics of what it saw in its training documents. Let's hit enter to see what tokens it comes up with as a continuation. ### Model Responses Here, it kind of actually answered the question and started to go off into some philosophical territory. Let's try it again. So, if I copy and paste "What is 2 plus 2?" and hit enter again, it just goes off again. Notice that every time you input it, the system starts from scratch. The system is stochastic, meaning for the same prefix of tokens, we're always getting a different answer. The reason for that is that we get this probability distribution and sample from it, leading to different outputs each time. ### Knowledge Representation Even though this model is not yet very useful for many applications, it is still valuable because, in the task of predicting the next token in the sequence, the model has learned a lot about the world and stored that knowledge in the parameters of the network. You can think of these **405 billion parameters** as a kind of compression of the internet. It's like a zip file, but it's not lossless compression; it's lossy compression. We can generate from it and elicit some of this knowledge by prompting the base model accordingly. For example, here's a prompt that might work to elicit some of that knowledge: "Here's my top 10 list of the top landmarks to see in Paris." Let's see if that works when I press enter. ### Eliciting Knowledge It started a list and is now giving some landmarks. Notice that it's trying to provide a lot of information. However, you might not be able to fully trust some of the information here. This is all just a recollection of internet documents, and the things that occur frequently in the internet data are probably more likely to be remembered correctly compared to things that happen infrequently. ### Example of Memorization I went to the Wikipedia page for "zebra" and copied the first sentence. Let’s see what kind of completion we get. When I click enter, the model produces an exact regurgitation of this Wikipedia entry. It is reciting this entry purely from memory, and it is possible that at some point, the model will stray away from the Wikipedia entry, but it has huge chunks of it memorized. The reason this happens is that for high-quality sources like Wikipedia, the model has probably done a few epochs on this data, meaning it has seen this web page multiple times. If it sees something too often, it will be able to recite it later from memory. ### Handling Unknown Information Now, let’s test the model with something it definitely has not seen during its training. The dataset has a knowledge cutoff until the end of **2023**, so it will not have seen documents after this point. If we prime the model with tokens from the future, it will continue the token sequence and take its best guess according to the knowledge it has in its parameters. For example, if I input, "The Republican Party kit Trump," let's see what it says next. The model might guess the running mate and who it's against. Let's hit enter. Here, it says Mike Pence was the running mate instead of JD Vance, and the ticket was against Hillary Clinton and Tim Kaine. ### Stochastic Outputs If we resample the identical prompt, we might get a different output. This time, it says the running mate was Ron DeSantis, and they ran against Joe Biden and Kamala Harris. This is an example of the model taking educated guesses and continuing the token sequence based on its knowledge. ### Practical Applications Even though this is a base model and not yet an assistant model, it can still be utilized in practical applications if you are clever with your prompt design. For example, I have a few-shot prompt with ten pairs of English words and their translations in Korean. When I hit completion, the model takes on the role of a translator and provides the correct translation. This demonstrates how you can build applications by being clever with your prompting, even with just a base model. ### Creating an Assistant Finally, there is a clever way to instantiate a whole language model assistant just by prompting. The trick is to structure a prompt to look like a conversation between a helpful AI assistant and a human. I turned to ChatGPT itself to help create this prompt. Here’s a conversation between an AI assistant and a human. The assistant is knowledgeable and capable of answering a wide variety of questions. Now, let’s input the actual query: "Why is the sky blue?" When we run this, the assistant responds with a scientific explanation. ### Summary of Key Points In summary, we have discussed the following: - We wish to train LLM assistants like ChatGPT. - The first stage is the pre-training stage, where we take internet documents, break them into tokens, and predict token sequences using neural networks. - The output of this stage is the base model, which is an internet document simulator on the token level. - We can use it in some applications, but we need to move to the second stage, called the post-training stage, to create an assistant. In the post-training stage, we will take our base model and continue training it on a dataset of conversations. This will allow the model to learn how to respond to human queries effectively. ### Conclusion The post-training stage is computationally much less expensive than the pre-training stage, and it allows us to create a more useful assistant model. By designing effective prompts and training on conversation datasets, we can transform the base model into a capable assistant. # Tokenization and Conversation Representation In this section, we will explore how conversations are represented for language models. Here, we have a two-turn conversation between a user and an assistant. Although it may look complicated, the process of turning this conversation into a token sequence is relatively straightforward. Ultimately, this conversation ends up being a one-dimensional sequence of **49 tokens**. ## Token Sequence Structure Different language models (LLMs) have slightly different formats or protocols for tokenization, and the landscape is somewhat chaotic at the moment. For example, GPT-4 uses a special token called **IM_START**, which stands for "Imaginary Monologue Start." Following this, you specify whose turn it is—like the user, represented by token **428**—and then you have an internal monologue separator. After that, the exact question is included, followed by the closing token **IM_END**. So, when a user asks, "What is 2 plus 2?" the token sequence is constructed as follows: - **IM_START** - User token (428) - Internal monologue separator - Tokens of the question - **IM_END** It's important to note that **IM_START** is not text; it's a special token that has never been trained on before. This token is introduced during the post-training stage to help the model learn the structure of conversations. ## Training on Token Sequences The key takeaway is that our conversations, which we think of as structured objects, are transformed into one-dimensional sequences of tokens. This allows us to apply the same training methods as before, predicting the next token in a sequence. ### Inference Process Once the model is trained on these conversation datasets, we can use it for inference. For instance, when you interact with ChatGPT, you might input a dialogue like "What is 2 plus 2?" and receive "2 plus 2 is four." The server constructs the context by adding tokens like **IM_START** and **IM_END** around the user input, and then the model samples from this context to generate a response. ## Data Sets for Training Now, let's discuss what these datasets look like in practice. The first significant effort in this direction was OpenAI's **InstructGPT** paper from 2022. This paper introduced the concept of fine-tuning language models on conversations. ### Human Labelers In this process, OpenAI hired human contractors from platforms like Upwork or Scale AI to create these conversations. These labelers were tasked with coming up with prompts and providing ideal assistant responses. Examples of prompts include: - "List five ideas for how to regain enthusiasm for my career." - "What are the top 10 science fiction books I should read next?" The labelers were given detailed instructions on how to create these ideal responses, emphasizing the importance of being helpful, truthful, and harmless. ### Data Collection While OpenAI never released the dataset for InstructGPT, there are open-source efforts attempting to replicate this setup. For example, the **Open Assistant** project involves people on the internet creating conversations similar to those in OpenAI's dataset. In this project, a user might ask, "Can you write a short introduction to the relevance of the term 'manop' in economics?" and then provide an ideal response. This process continues with follow-up questions, creating a structured dataset for training. ## The Role of Language Models The state of the art has evolved over the past few years. Nowadays, it's common for human labelers to use existing language models to generate responses, which they then edit. This has led to the creation of datasets like **UltraChat**, which consists of millions of conversations, primarily synthetic but with some human involvement. ### Understanding AI Responses When you interact with a model like ChatGPT, it's essential to understand that the responses are not generated by a magical AI. Instead, they are statistically aligned with the training set, which is based on human labelers following specific instructions. For example, if you ask, "Recommend the top five landmarks to see in Paris," the model's response is likely a statistical simulation of what a human labeler would have provided based on their research. ## LLM Psychology: Hallucinations One significant issue with language models is **hallucinations**, where they fabricate information. This problem has been prevalent in earlier models but has improved over time. ### Understanding Hallucinations Hallucinations occur because the model is trained on confident responses, even when it doesn't know the answer. For instance, if you ask about a fictional character, the model may confidently provide a fabricated answer rather than admitting it doesn't know. To mitigate this, it's crucial to include examples in the dataset where the correct response is that the model doesn't know the answer. This requires empirical probing to understand what the model knows. ### Addressing Hallucinations in Llama 3 Meta's Llama 3 series of models has made strides in addressing hallucinations. By incorporating examples where the model admits it doesn't know something, they aim to improve the accuracy of responses. In summary, understanding the tokenization process, the role of human labelers, and the challenges of hallucinations is essential for grasping how language models like ChatGPT operate. # Addressing Hallucinations in Language Models In the context of language models, hallucinations refer to instances where the model generates incorrect or fabricated information. Meta has introduced a procedure to address this issue, which they refer to as **factuality**. This involves interrogating the model to determine what it knows and doesn't know, effectively mapping the boundaries of its knowledge. ## Interrogation Process The process begins by taking a random document from the training set and extracting a paragraph. From this paragraph, questions are generated using a language model (LLM). For example, if we take a paragraph about a sports figure, we might generate questions like: - For which team did he play? - How many cups did he win? Once we have these questions, we can interrogate the model to see if it knows the answers. This is done by comparing the model's responses to the correct answers. If the model consistently provides the correct answer, we can conclude that it knows the information. Conversely, if it provides incorrect answers, we recognize that it doesn't know. ### Example of Interrogation 1. **Question**: For which team did he play? - **Model's Answer**: Buffalo Sabers. - **Correct Answer**: Buffalo Sabers. - **Conclusion**: The model knows. 2. **Question**: How many Stanley Cups did he win? - **Model's Answer**: Four. - **Correct Answer**: Two. - **Conclusion**: The model doesn't know. If the model fails to provide the correct answer after several attempts, we can create a new entry in the training set indicating that the correct response is "I don't know" or "I don't remember." This allows the model to learn to express uncertainty when it lacks knowledge. ## Enhancing Model Responses While acknowledging uncertainty is one mitigation strategy, we can also enhance the model's ability to provide factual answers. When faced with a question it doesn't know, the model can be designed to perform a web search to refresh its memory. ### Implementing Web Search To facilitate this, we introduce special tokens that the model can emit when it needs to search for information. For example: - **Search Start**: Indicates the beginning of a search query. - **Search End**: Indicates the end of the search query. When the model encounters a question it cannot answer, it emits the **Search Start** token followed by the query, and then the **Search End** token. The inference program recognizes these tokens and pauses the model's output to perform a web search. ### Example of Web Search 1. **User Query**: "How many Stanley Cups did Dominic Hasek win?" 2. **Model Response**: Emits **Search Start** and the query. 3. **Web Search**: The program searches Bing or Google, retrieves relevant information, and pastes it into the model's context window. 4. **Final Response**: The model generates a response based on the newly acquired information. This method allows the model to access up-to-date information, effectively refreshing its working memory and improving the accuracy of its responses. ## Training the Model to Use Tools To ensure the model can effectively use these tools, we need to provide training examples that demonstrate how to structure queries and utilize the web search function. With sufficient examples, the model learns to recognize when to use the search tool and how to formulate effective queries. ### Practical Implications When interacting with language models, it's beneficial to provide context directly in the prompt. For instance, instead of asking the model to summarize a chapter from a book it may or may not remember, you can paste the chapter text directly into the prompt. This gives the model immediate access to the information, leading to higher-quality responses. ## Understanding Self-Knowledge in Language Models It's important to note that language models do not possess a persistent sense of self. They operate by processing tokens and generating responses based on statistical patterns learned during training. When asked about their identity or origin, they may provide answers based on the data they were trained on, but these responses are not reflective of any true self-awareness. ### Example of Misleading Responses When asked, "What model are you?" a language model might respond with something like, "I was built by OpenAI based on the GPT-3 model." This response is not necessarily accurate; it reflects the model's statistical best guess based on its training data rather than factual knowledge. ## Conclusion In summary, addressing hallucinations in language models involves a combination of interrogating the model to understand its knowledge boundaries and enhancing its ability to retrieve accurate information through web searches. By implementing these strategies and providing clear training examples, we can significantly improve the factuality and reliability of language model responses. to ask it again and see if it gives a consistent answer. ### Example of Inconsistency When I ask, "Is 9.11 bigger than 9.9?" the model might initially say yes, but then it could change its answer upon further questioning. This inconsistency can be frustrating, especially when the model is capable of solving complex problems but struggles with basic comparisons. ### Understanding the Limitations The key takeaway here is that while these models are powerful, they have limitations. They can perform well on complex tasks but may falter on simpler ones due to their reliance on patterns learned from training data rather than true understanding. ### Conclusion In summary, when using language models, it's essential to be aware of their cognitive deficits, such as difficulties with counting, spelling, and basic reasoning. By understanding these limitations, we can better navigate interactions with these models and utilize tools like code interpreters to enhance their performance. Always remember to distribute reasoning across tokens and lean on tools whenever possible to mitigate potential errors. # Understanding Reinforcement Learning in Language Models Okay, even though it might look larger, here it doesn't even correct itself in the end. If you ask many times, sometimes it gets it right too. But how is it that the model can do so great at Olympiad-grade problems but then fail on very simple problems like this? ## Cognitive Distractions This one is, as I mentioned, a little bit of a head-scratcher. It turns out that a bunch of people studied this in depth. I haven't actually read the paper, but what I was told by this team was that when you scrutinize the activations inside the neural network, when you look at some of the features and what neurons turn on or off, a bunch of neurons inside the neural network light up that are usually associated with Bible verses. So, I think the model is kind of reminded that these almost look like Bible verse markers, and in a Bible verse setting, 9.11 would come after 99.9. Basically, the model finds it cognitively very distracting that in Bible verses, 9.11 would be greater. Even though here it's actually trying to justify it and come up with the answer mathematically, it still ends up with the wrong answer. ## Stochastic Systems So, it basically just doesn't fully make sense, and it's not fully understood. There are a few jagged issues like that. That's why we treat this as what it is—a stochastic system that is really magical, but you can't fully trust it. You want to use it as a tool, not as something that you can just let rip on a problem and copy-paste the results. ## Stages of Training Large Language Models Now, we have covered two major stages of training large language models. We saw that in the first stage, called the **pre-training stage**, we are basically training on internet documents. When you train a language model on internet documents, you get what's called a **base model**, which is essentially an internet document simulator. This takes many months to train on thousands of computers and is kind of a lossy compression of the internet. It's extremely interesting but not directly useful because we don't want to sample internet documents; we want to ask questions of an AI and have it respond to our questions. ## Creating an Assistant For that, we need an assistant. We saw that we can construct an assistant in the process of **post-training**, specifically in the process of **supervised fine-tuning** (SFT). In this stage, it's algorithmically identical to pre-training; the only thing that changes is the dataset. Instead of internet documents, we now want to create and curate a very nice dataset of conversations. We want millions of conversations on all kinds of diverse topics between a human and an assistant. Fundamentally, these conversations are created by humans, so humans write the prompts and ideal responses based on labeling documentation. ## Modern Data Collection In the modern stack, it's not done fully and manually by humans; they actually now have a lot of help from these tools. We can use language models to help us create these datasets, and that's done extensively. But fundamentally, it's all still coming from human curation at the end. We create these conversations, which now become our dataset. We fine-tune on it or continue training on it, and we get an assistant. Then we shifted gears and started talking about some of the cognitive implications of what this assistant is like. ## Hallucinations and Mitigations We saw that, for example, the assistant will hallucinate if you don't take some sort of mitigations towards it. Hallucinations would be common, and we looked at some of the mitigations for those hallucinations. The models are quite impressive and can do a lot of stuff in their head, but they can also lean on tools to become better. For example, we can lean on a web search to hallucinate less and maybe bring up some more recent information, or we can lean on tools like a code interpreter so the LLM can write some code and actually run it to see the results. ## Reinforcement Learning Stage Now, what I'd like to do is cover the last and major stage of this pipeline, which is **reinforcement learning**. Reinforcement learning is still thought to be under the umbrella of post-training, but it is the last major stage and a different way of training language models. ### Motivation for Reinforcement Learning Let me first motivate the reinforcement learning stage and what it looks like on a high level. Just like you went to school to become really good at something, we want to take large language models through school. When we're working with textbooks in school, you'll see that there are three major pieces of information in these textbooks: 1. **Exposition**: Most of the text is background knowledge. As you read through this exposition, you can think of it roughly as training on that data. This is equivalent to pre-training, where we build a knowledge base. 2. **Problems and Worked Solutions**: A human expert provides not just a problem but also works through the solution. This is like having an ideal response for an assistant, showing how to solve the problem in full form. This corresponds to having the SFT model. 3. **Practice Problems**: These are critical for learning. You get a problem description but not the solution, only the final answer in the answer key. You practice solving the problem yourself, relying on background information and imitation of human experts. ## Reinforcement Learning in Practice Now, let's go back to the problem we worked with previously for a concrete example. Emily buys three apples and two oranges; each orange is $2, and the total cost of all the fruit is $13. What is the cost of each apple? Here are four possible candidate solutions, and they all reach the answer of $3. If I am the human data labeler creating a conversation to be entered into the training set, I don't actually know which of these conversations to add to the dataset. Some set up a system of equations, some talk through it in English, and some skip right to the solution. ## Evaluating Solutions The first purpose of a solution is to reach the right answer, but there's also a secondary purpose: making it nice for the human. If we only care about the final answer, which of these is the optimal solution for the LLM to reach the right answer? We don't know. For example, in one solution, asking for a lot of computation on a single token might lead to mistakes. Conversely, many tokens that I create might be trivial for the LLM, wasting tokens. ## Discovering Effective Solutions Long story short, we are not in a good position to create these token sequences for the LLM. Our knowledge is not the LLM's knowledge. The LLM has a ton of knowledge in math and physics, and in many ways, it knows more than I do. We want the LLM to discover the token sequences that work for it. It needs to find for itself what token sequence reliably gets to the answer given the prompt, and it needs to discover that in the process of reinforcement learning and trial and error. ### Reinforcement Learning Process In reinforcement learning, we try many different kinds of solutions and see which work well. We take the prompt, run the model, and inspect the solution. If the model gets the correct answer, we encourage the kinds of solutions that lead to right answers. For example, if we generate 15 solutions and only four get the right answer, we want to train on those sequences. The model practices and learns from its own solutions, discovering what works for it without human intervention. ## Conclusion In summary, the process of reinforcement learning is about guessing and checking. We generate many different types of solutions, check them, and do more of what worked in the future. This is how we train large language models, akin to how we train children, but with a focus on the unique capabilities and knowledge of the models themselves. # Reinforcement Learning in Language Models So, this stage is a lot more early and nuanced, and the reason for that is because I actually skipped over a ton of little details here in this process. The high-level idea is very simple: it's trial and error learning, but there are a ton of details and mathematical nuances to exactly how you pick the solutions that are the best, how much you train on them, what the prompt distribution is, and how to set up the training run such that this actually works. There are a lot of little details and knobs to the core idea that is very simple, and getting the details right here is not trivial. A lot of companies, like OpenAI and other LLM providers, have experimented internally with reinforcement learning fine-tuning for LLMs for a while, but they've not talked about it publicly. It's all kind of done inside the company. That's why the paper from DeepMind that came out very recently was such a big deal. This paper from a company called DeepSeek in China really talked very publicly about reinforcement learning fine-tuning for large language models and how incredibly important it is for large language models, bringing out a lot of reasoning capabilities in the models. ## DeepSeek R1 Paper Overview This paper reinvigorated public interest in using RL for LLMs and provided many of the necessary details to reproduce their results and actually get this stage to work for large language models. Let me take you briefly through this DeepSeek R1 paper and what happens when you correctly apply RL to language models. The first thing I'll scroll to is this kind of figure two here, where we are looking at the improvement in how the models are solving mathematical problems. This is the accuracy of solving mathematical problems, and we can see the kinds of problems that are actually being measured here. These are simple math problems. You can pause the video if you like, but these are the kinds of problems the models are being asked to solve. In the beginning, they're not doing very well, but as you update the model with thousands of steps, their accuracy continues to climb. The models are improving and solving these problems with higher accuracy as you do this trial and error on a large dataset of these kinds of problems. ## Emergent Properties of Optimization Even more incredible than the quantitative results of solving these problems with higher accuracy is the qualitative means by which the model achieves these results. Later on in the optimization, the model seems to be using a longer average length per response. The model learns to create very long solutions. Why are these solutions very long? We can look at them qualitatively here. The model discovers that it works better for accuracy to try out lots of ideas, try something from different perspectives, retrace, reframe, and backtrack. It's doing a lot of the things that you and I do in the process of problem-solving for mathematical questions. This is rediscovered in the model's head—not something that can be hardcoded into the ideal assistant response. This is only something that can be discovered in the process of reinforcement learning because you wouldn't know what to put here. It turns out to work for the model and improves its accuracy in problem-solving. ## Chains of Thought The model learns what we call these **chains of thought** in your head, and it's an emergent property of the optimization. That's what's bloating up the response length, but it's also what's increasing the accuracy of problem-solving. The model is discovering ways to think; it's learning cognitive strategies for manipulating a problem, approaching it from different perspectives, pulling in analogies, and trying out many different things over time. Now, let's go back to the problem we've been working with and see what it would look like for a reasoning or thinking model to solve that problem. ### Example Problem Recall that this is the problem we've been working with: Emily buys three apples and two oranges; each orange costs $2, and the total is $13. I need to find out the cost of each apple. When I pasted this into ChatGPT-4, I got a certain response. Now, let's take a look at what happens when you give this same query to a reasoning or thinking model trained with reinforcement learning. This model described in the DeepSeek paper is available on chat.deepseek.com. Make sure that the DeepSeek button is turned on to get the R1 model. Let's paste it here and run it. ### Model Output Here's what it says: "Let me try to figure this out. So, Emily buys three apples and two oranges; each orange costs $2, and the total is $13. I need to find out the cost of each apple." As you're reading this, you can't escape thinking that this model is thinking. It pursues the solution, derives that it must cost $3, and then says, "Wait a second, let me check my math again to be sure." It tries it from a slightly different perspective and confirms, "Yep, all that checks out. I think that's the answer. I don't see any mistakes." Then it explores another way to approach the problem, maybe setting up an equation, and concludes that each apple is indeed $3. ### Presentation of Solutions Once it sorts out the thinking process, it writes up a nice solution for the human. This is more about the correctness aspect and the presentation aspect, where it writes it out nicely and boxes in the correct answer at the bottom. What's incredible about this is we get this thinking process of the model, and this is what's coming from the reinforcement learning process. This is what's bloating up the length of the token sequences—they're doing thinking and trying different ways, which is giving you higher accuracy in problem-solving. ## Concerns About Data Privacy The last point I wanted to make is that some people are a little nervous about putting sensitive data into chat.deepseek.com because this is a Chinese company. People are a bit careful with that. However, DeepSeek R1 is an open-source model available for anyone to download and use. You won't be able to run it in full precision on a MacBook or local device because it's a fairly large model, but many companies are hosting the full model. One of those companies I like to use is called Together. When you go to Together, sign up, and go to playgrounds, you can select the DeepSeek R1 model. These are all state-of-the-art models, similar to the Hugging Face inference playground we've been using. ## Summary of Key Points In summary, we've talked about reinforcement learning and the fact that thinking emerges in the process of optimization when we run RL on many math and code problems that have verifiable solutions. These thinking models can be accessed in DeepSeek or any inference provider like Together. You can also find them in ChatGPT under the 01 or 03 models, but these GPT-4 models are mostly supervised fine-tuning models. If you have a prompt that requires advanced reasoning, you should probably use some of the thinking models or at least try them out. For simpler questions, using GPT-4 might suffice. ## Conclusion Reinforcement learning is an exciting stage in the development of large language models, and getting the details right is crucial. The frontier of LLM research is focused on creating diverse prompt distributions that allow models to practice their thinking and reasoning capabilities. # Humor and Reinforcement Learning in Language Models Okay, we can try something else. Why don't pelicans ever pay for their drinks? Because they always **bill** it to someone else! Haha! ## The Challenge of Humor These models are obviously not very good at humor. I think it's pretty fascinating because humor is secretly very difficult. The models have the capability, but the problem we face is how to score these jokes. In principle, we could get a human to look at all these jokes, just like I did right now. The problem with that is, if you are doing reinforcement learning, you're going to be doing many thousands of updates. For each update, you want to look at thousands of prompts, and for each prompt, you want to potentially look at hundreds or thousands of different kinds of generations. There are just way too many of these to look at. ## The Need for Automation In principle, you could have a human inspect all of them and score them, deciding which ones are funny. However, this is an unscalable strategy. We need some kind of automatic strategy for doing this. One solution proposed in a paper introduced what's called **Reinforcement Learning from Human Feedback (RLHF)**. This paper was from OpenAI, and many of the authors are now co-founders of Anthropic. It proposed an approach for doing reinforcement learning in unverifiable domains. ### The RLHF Approach Let's take a look at how that works. Here’s a cartoon diagram of the core ideas involved. The native approach is if we had infinite human time, we could run RL in these domains just fine. For example, we could run RL as usual if we had infinite humans. We would want to do 1,000 updates, where each update would be on 1,000 prompts, and for each prompt, we would have 1,000 rollouts that we're scoring. However, in the process of doing this, I would need to ask a human to evaluate a joke a total of **1 billion times**. That's a lot of people looking at really terrible jokes, so we don't want to do that. ### Introducing the Reward Model Instead, we take the RLHF approach. The core trick is that of **indirection**. We involve humans just a little bit. We train a separate neural network called a **reward model** that imitates human scores. We ask humans to score rollouts, and then we imitate those human scores using a neural network. This neural network becomes a simulator of human preferences. Now that we have a simulator, we can query it as many times as we want, and it's an automatic process. We can do reinforcement learning with respect to the simulator. ### Training the Reward Model Here’s a hypothetical example of what training the reward model would look like. We have a prompt like "Write a joke about pelicans," and then we have five separate rollouts—five different jokes. The first thing we do is ask a human to order these jokes from best to worst. This human thought that one joke was the funniest, so they ranked it number one, and so on. Instead of giving precise scores, we ask for an ordering, which is an easier task for a human. Now, we ask the reward model to score these jokes. The reward model takes the prompt and a candidate joke as inputs. The output is a single number thought of as a score, ranging from 0 to 1. ### Comparing Scores We compare the scores given by the reward model with the ordering given by the human. There’s a precise mathematical way to calculate this, but the intuition is that we nudge the predictions from the model using a neural network training process. As we update the reward model on human data, it becomes a better simulator of the scores and orders that humans provide. This way, we’re not asking humans to look at a billion jokes; we’re asking them to look at maybe 5,000 jokes in total and just give the ordering. ## Upsides of RLHF The upside of RLHF is that it allows us to run reinforcement learning, which is incredibly powerful, in arbitrary domains, including unverifiable ones like summarization, poem writing, and joke writing. Empirically, we see that applying RLHF improves the performance of the model. My best guess for why this happens is that it’s easier for humans to discriminate than to generate. ### Easier Tasks for Humans In supervised fine-tuning (SFT), we ask humans to generate ideal responses, which can be difficult. In contrast, with RLHF, we ask people to order responses, which is a much easier task. This allows for higher accuracy data because we’re not asking people to do the generation task; we’re just trying to get them to distinguish between creative writings. ## Downsides of RLHF However, RLHF comes with significant downsides. The main issue is that we are doing reinforcement learning not with respect to actual human judgment but with respect to a lossy simulation of humans. This simulation could be misleading. ### The Problem of Gaming the Model Another subtle issue is that reinforcement learning is extremely good at discovering ways to game the model. The reward model we construct gives scores, but these models are complex systems. There are ways to find inputs that were not part of their training set, which can yield very high scores in a misleading way. For example, after a few hundred updates, the jokes about pelicans might improve initially, but then they could dramatically fall off a cliff, leading to nonsensical results. ### Adversarial Examples These nonsensical results are called **adversarial examples**. They are specific inputs that exploit the model's weaknesses and yield high scores without making sense. If we try to correct this by adding these nonsensical examples to the dataset and giving them low scores, we will always find infinite adversarial examples hiding in the model. ## Conclusion on RLHF In summary, RLHF is not real reinforcement learning in the magical sense. It can improve the model slightly, but it lacks the robustness of true RL. It’s more like fine-tuning that slightly improves your model. We covered the three major stages of training these models: pre-training, supervised fine-tuning, and reinforcement learning. Each corresponds to processes we use for teaching children. ### Future Capabilities Looking ahead, models will rapidly become **multimodal**. They will not just handle text but also operate over audio and images. This will enable natural conversations and interactions. As a baseline, we can tokenize audio and images and apply the same approaches we've discussed. For example, we can tokenize slices of the spectrogram of audio signals and patches of images, creating streams of tokens that represent audio, images, and text simultaneously. This is an exciting direction for the future of language models! # Future of Multimodal Language Models Multimodality is an area of great interest in the field of AI. Currently, most work involves handing individual tasks to models, almost like serving them on a silver platter. The models perform these tasks, but they are not yet capable of organizing coherent executions of multiple tasks over extended periods. They struggle to string together tasks to perform longer-running jobs, but improvements are on the horizon. ## Emergence of Agents As we move forward, we can expect to see the development of **agents** that can perform tasks over time. These agents will require supervision, allowing humans to monitor their work and report progress periodically. This shift will lead to long-running tasks that take not just seconds but potentially minutes or hours to complete. However, it's important to remember that these models are not infallible, and supervision will remain essential. ### Human to Agent Ratios In factories, there's a concept of the human-to-robot ratio for automation. Similarly, in the digital space, we will likely see a human-to-agent ratio, where humans supervise agent tasks in the digital domain. ## Pervasiveness and Integration The integration of AI will become more pervasive and invisible, embedded in various tools and applications. Currently, models cannot take actions on behalf of users, but this is changing. For instance, the launch of **ChatGPT's Operator** allows users to hand off control to the model for keyboard and mouse actions. ## Research Opportunities There is still much research to be done in this domain. One area of interest is **test-time training**. Traditionally, models undergo a training stage where parameters are tuned for task performance. Once deployed, these models are fixed and do not learn from their interactions during inference. Unlike humans, who can learn and adapt, current models lack this capability. ### Context Window Limitations The context window is a finite and precious resource. As we tackle longer-running multimodal tasks, the context windows will need to grow significantly. The only current solution is to extend the context windows, but this approach may not scale effectively for complex tasks. New ideas are needed to address these challenges. ## Staying Updated in the Field To keep track of progress in AI, here are three valuable resources: 1. **El Marina**: This is an LLM leaderboard that ranks models based on human comparisons. Users prompt models and judge which provides better answers, leading to a ranking system. For example, Google Gemini currently ranks at the top, followed closely by OpenAI. 2. **AI News Newsletter**: Produced by Swix and friends, this newsletter is comprehensive and updated almost daily. It includes human-curated content and automated summaries, ensuring you stay informed about the latest developments. 3. **X (formerly Twitter)**: Following trusted individuals in the AI community on X can provide real-time updates and insights. ## Accessing Models For proprietary models, visit the respective websites of the LLM providers. For open-weight models like Deep Seek, you can use inference providers such as **Together**. This platform allows you to interact with various models, including open models. ### Running Models Locally For smaller models, you can run them locally on your computer. While larger models like Deep Seek may not be feasible, distilled versions can be run at lower precision. **LM Studio** is a popular app for this purpose, allowing you to load and interact with models directly on your device. ## Understanding Model Responses When you enter a query into a model like ChatGPT, it is first tokenized. The model processes this token sequence and generates a response based on its training. The underlying mechanism involves a neural network that simulates a data labeler, producing responses based on learned patterns. ### Limitations of Neural Networks It's important to recognize that these models do not function like human brains. They can suffer from hallucinations and inconsistencies, leading to errors in reasoning or arithmetic. This "Swiss cheese" capability means that while they can perform many tasks well, they can also make mistakes. ## Conclusion In summary, the future of multimodal language models is promising, with advancements in agent capabilities and integration into everyday tools. However, it's crucial to remain aware of their limitations and use them as tools rather than relying on them completely. By checking their work and verifying outputs, you can leverage these models effectively in your tasks. Thank you for watching, and I hope you found this information useful!
Залогинтесь, что бы оставить свой комментарий