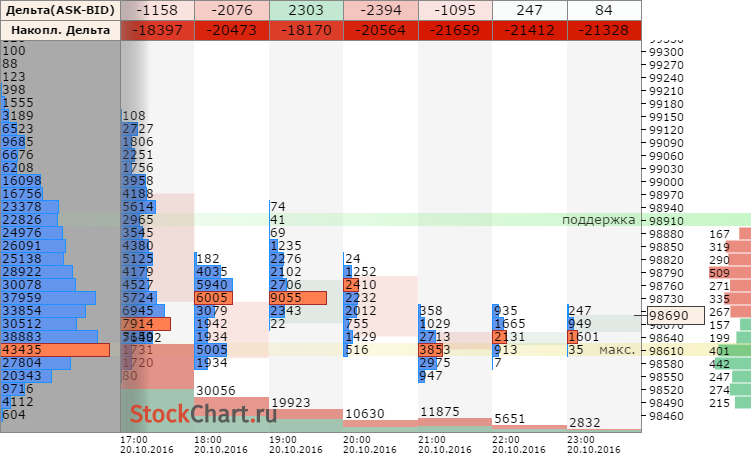
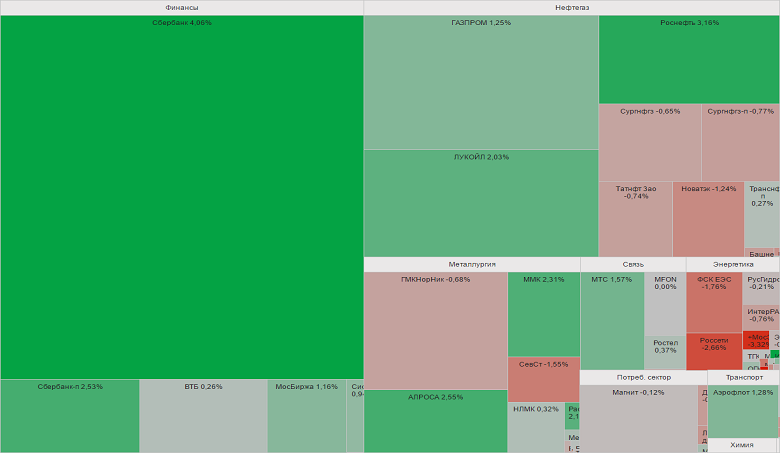
 | | | |||||||||||
|
|
||||||||||||
| | | |||||||||||||||
|
|
||||||||||||||||



Техническая поддержка
ONLINE
| | | |||||||||||||||||
|
|
||||||||||||||||||
How I use LLMs
ruticker 04.03.2025 15:24:33 Recognized text from YouScriptor channel Andrej Karpathy
Recognized from a YouTube video by YouScriptor.com, For more details, follow the link How I use LLMs
# Hi everyone! In this video, I would like to continue our general audience series on large language models like ChatGPT. In the previous video, a deep dive into LLMs that you can find on my YouTube, we went into a lot of the under-the-hood fundamentals of how these models are trained and how you should think about their cognition or psychology. Now, in this video, I want to go into more practical applications of these tools. I want to show you lots of examples, take you through all the different settings that are available, and demonstrate how I use these tools and how you can also use them in your own life and work. So, let's dive in! ## Overview of ChatGPT First of all, the web page that I have pulled up here is **chat.openai.com**. As you might know, ChatGPT was developed by OpenAI and deployed in 2022. This was the first time that people could actually talk to a large language model through a text interface, and this went viral all over the internet. This was huge! Since then, though, the ecosystem has grown a lot. I'm going to be showing you a lot of examples of ChatGPT specifically, but now in 2025, there are many other apps that are kind of like ChatGPT, and this is now a much bigger and richer ecosystem. In particular, I think ChatGPT by OpenAI is the original gangster incumbent—it's the most popular and most feature-rich, also because it's been around the longest. But there are many other clones available. I would say it's not too unfair to say that in some cases, there are unique experiences that are not found in ChatGPT, and we're going to see examples of those. For example, big tech has followed with a lot of ChatGPT-like experiences, such as **Gemini** from Google and **Copilot** from Microsoft. There are also a number of startups, like **Anthropic**, which has **Claude**, and **xAI**, which is Elon Musk's company that has **Gro**. There are many others. All of these companies are based in the United States, while **DeepMind** is a Chinese company and **LChat** is a French company. ## Keeping Track of Models Now, where can you find these and how can you keep track of them? Well, number one, on the internet somewhere, but there are some leaderboards. In the previous video, I showed you **Chatbot Arena** as one of them. Here, you can come to see a ranking of different models and their strength or ELO score. This is one place where you can keep track of them. Another place is the **Scale AI leaderboard**, where you can also see different kinds of evaluations and how well different models rank on a wide variety of tasks. So, understand that the ecosystem is fairly rich, but for now, I'm going to start with OpenAI because it is the incumbent and is the most feature-rich. I will show you others over time as well. ## Interacting with ChatGPT Let's start with ChatGPT. What is this text box, and what do we put in here? The most basic form of interaction with the language model is that we give it text, and then we get some text back in response. For example, we can ask it to write a haiku about what it's like to be a large language model. This is a good kind of example to ask for a language model because these models are really good at writing—writing haikus, poems, cover letters, resumes, or email replies. They're just good at writing. When we ask for something like this, what happens looks as follows: > Words flow like a stream, > Endless echo, > Never mind, ghost of thought unseen. It's pretty dramatic, but what we're seeing here in ChatGPT is something that looks a bit like a conversation that you would have with a friend. These are kind of like chat bubbles. Now, we saw in the previous video that what's going on under the hood here is that this is what we call a user query. This piece of text and the response from the model are chopped up into little text chunks that we call tokens. This sequence of text is, under the hood, a one-dimensional token sequence. The way we can see those tokens is by using an app like **Tik Tokenizer**. Making sure that **GPT-4** is selected, I can paste my text here, and this is actually what the model sees under the hood. My piece of text to the model looks like a sequence of exactly 15 tokens, and these are the little text chunks that the model sees. Now, there's a vocabulary here of roughly 200,000 possible tokens, and these are the token IDs corresponding to all these little text chunks that are part of my query. You can play with this and update it, and you can see that, for example, this is case-sensitive—you would get different tokens, and you can kind of edit it and see live how the token sequence changes. So, our query was 15 tokens, and then the model response is right here, and it responded back to us with a sequence of exactly 19 tokens. Now, because this is a conversation and we want to maintain a lot of the metadata that makes up a conversation object, this is not all that's going on under the hood. We saw in the previous video a little bit about the conversation format. It gets a little bit more complicated in that we have to take our user query and actually use this chat format. Let me delete the system message; I don't think it's very important for the purposes of understanding what's going on. Let me paste my message as the user and then paste the model response as an assistant. Here we have it as it actually happens under the hood. There are all these special tokens that basically begin a message from the user, and then the user says, and this is the content of what we said, and then the user ends, and then the assistant begins and says this, etc. Now, the precise details of the conversation format are not important. What I want to get across here is that what looks to you and me as little chat bubbles going back and forth, under the hood, we are collaborating with the model, and we're both writing into a token stream. These two bubbles back and forth were a sequence of exactly 42 tokens. Under the hood, I contributed some of the first tokens, and then the model continued the sequence of tokens with its response. We could alternate and continue adding tokens here, and together we're building out a token window—a one-dimensional token sequence. ## Context Window and Model Interaction When I click "New Chat" here, that wipes the token window, resets the tokens to basically zero again, and restarts the conversation from scratch. The cartoon diagram that I have in my mind when I'm speaking to a model looks something like this: when we click "New Chat," we begin a token sequence. This is a one-dimensional sequence of tokens. The user can write tokens into this stream, and then when we hit enter, we transfer control over to the language model, and the language model responds with its own token streams. The language model has a special token that basically says something along the lines of "I'm done." When it emits that token, the ChatGPT application transfers control back to us, and we can take turns. Together, we are building out the token stream, which we also call the context window. The context window is kind of like this working memory of tokens, and anything that is inside this context window is directly accessible by the model. ## Understanding the Language Model Now, what is this entity that we are talking to, and how should we think about it? This language model, as we saw, is trained in two major stages: the pre-training stage and the post-training stage. The pre-training stage is like taking all of the internet, chopping it up into tokens, and then compressing it into a single kind of zip file. But the zip file is not exact; it's a lossy and probabilistic zip file because we can't possibly represent all of the internet in just one terabyte of zip file—there's just way too much information. So, we just kind of get the gist or the vibes inside this zip file. What actually is inside the zip file are the parameters of a neural network. For example, a one terabyte zip file would correspond to roughly one trillion parameters inside this neural network. What this neural network is trying to do is take tokens and predict the next token in a sequence, but it's doing that on internet documents. It's kind of like this internet document generator. In the process of predicting the next token in a sequence on the internet, the neural network gains a huge amount of knowledge about the world, and this knowledge is all represented and compressed inside the one trillion parameters of this language model. The pre-training stage is also fairly costly. This can be many tens of millions of dollars—say, like three months of training and so on. This is a costly, long phase, and for that reason, this phase is not done that often. For example, GPT-4 was pre-trained probably many months ago, maybe even a year ago by now, and that's why these models are a little bit out of date. They have what's called a knowledge cutoff because that knowledge cutoff corresponds to when the model was pre-trained, and its knowledge only goes up to that point. Some knowledge can come into the model through the post-training phase, which we'll talk about in a second, but roughly speaking, you should think of these models as a little bit out of date because pre-training is way too expensive and happens infrequently. So, any kind of recent information—like if you wanted to talk to your model about something that happened last week—we're going to need other ways of providing that information to the model because it's not stored in the knowledge of the model. ## Post-Training Phase After pre-training, there's a second stage called post-training. The post-training stage is really about attaching a smiley face to this zip file because we don't want to generate internet documents; we want this thing to take on the persona of an assistant that responds to user queries. That's done in a process of post-training where we swap out the dataset for a dataset of conversations that are built out by humans. This is basically where the model takes on this persona so that we can ask questions and it responds with answers. It takes on the style of an assistant through post-training, but it has the knowledge of all of the internet from pre-training. These two are combined in this artifact. ## Summary of ChatGPT If I had to summarize what we talked about so far, I would probably do it in the form of an introduction to ChatGPT in a way that I think you should think about it: > Hi, I'm ChatGPT. I am a one terabyte zip file. My knowledge comes from the internet, which I read in its entirety about six months ago, and I only remember vaguely. My winning personality was programmed by example by human labelers at OpenAI. The personality is programmed in post-training, and the knowledge comes from compressing the internet during pre-training. This knowledge is a little bit out of date, and it's probabilistic and slightly vague. Some of the things that are mentioned very frequently on the internet, I will have a much better recollection of than some of the things that are discussed very rarely—very similar to what you might expect with a human. Now, let's talk about some of the repercussions of this entity and how we can talk to it and what kinds of things we can expect from it. ## Real Examples I'd like to use real examples when we actually go through this. For example, this morning, I asked ChatGPT the following: "How much caffeine is in one shot of Americano?" I was curious because I was comparing it to matcha. ChatGPT told me that this is roughly 63 mg of caffeine or so. The reason I'm asking ChatGPT this question is that, number one, I'm not asking about any knowledge that is very recent, so I do expect that the model has read about how much caffeine there is in one shot. I don't think this information has changed too much. Number two, I think this information is extremely frequent on the internet. This kind of question and this kind of information has occurred all over the place on the internet, and because there are so many mentions of it, I expect the model to have a good memory of it in its knowledge. There's no tool use, and the model—the zip file—responded that there's roughly 63 mg. Now, I'm not guaranteed that this is the correct answer; this is just its vague recollection of the internet. But I can go to primary sources and maybe look up "caffeine in Americano" and verify that, yes, it looks to be about 63 mg, which is roughly right. You can look at primary sources to decide if this is true or not. Here's an example of a conversation I had two days ago. I was a bit sick, had a runny nose, and wanted to get meds that help with that. ChatGPT told me a bunch of stuff, and I wanted my nose to not be runny, so I gave it a clarification based on what it said. Then it kind of gave me some of the things that might be helpful with that. I looked at some of the meds that I have at home and asked, "Does DayQuil or NyQuil work?" It went over the ingredients of DayQuil and NyQuil and whether or not they helped mitigate a runny nose. Now, when these ingredients are coming here, again remember we are talking to a zip file that has a recollection of the internet. I'm not guaranteed that these ingredients are correct, and in fact, I actually took out the box and looked at the ingredients to make sure that NyQuil's ingredients were exactly these ingredients. I'm doing that because I don't always fully trust what's coming out here, right? This is just a probabilistic statistical recollection of the internet. But that said, conversations about DayQuil and NyQuil are very common, and probably there's tons of information about a lot of this on the internet. This is the kind of thing that the model has a pretty good recollection of, so actually, these were all correct. Then I asked, "Okay, well, I have NyQuil. How fast would it act roughly?" and it kind of told me, and then it basically said yes. So this is a good example of how ChatGPT was useful to me. It was a knowledge-based query, and this knowledge isn't recent; it's all coming from the knowledge of the model. I think this is common information, and this is not a high-stakes situation. I'm checking ChatGPT a little bit, but also this is not a high-stakes situation, so no big deal. I popped a NyQuil, and indeed it helped. ## Notes on Interaction At this point, I want to make two notes. The first note is that naturally, as you interact with these models, you'll see that your conversations are growing longer. Anytime you are switching topics, I encourage you to always start a new chat. When you start a new chat, as we talked about, you are wiping the context window of tokens and resetting it back to zero. If it is the case that those tokens are not any more useful to your next query, I encourage you to do this because these tokens in the window are expensive. They are expensive in kind of two ways: 1. If you have lots of tokens here, then the model can actually find it a little bit distracting. If this was a lot of tokens, the model might be distracted by all the tokens in the past when it is trying to sample tokens much later on. So it could be distracting, and it could actually decrease the accuracy of the model and its performance. 2. The more tokens are in the window, the more expensive it is—by a little bit, not by too much—to sample the next token in the sequence. Your model is actually slightly slowing down; it's becoming more expensive to calculate the next token, and the more tokens there are, the more expensive it is. So think of the tokens in the context window as a precious resource. Keep it as short as you can, and you can expect that to work faster and slightly better. Of course, if the information is related to your task, you may want to keep it in there, but I encourage you to start a new chat whenever you are switching topics. The second thing is that I always encourage you to keep in mind what model you are actually using. Here in the top left, we can drop down and see that we are currently using **GPT-4**. Now, there are many different models of many different flavors, and there are too many, actually, but we'll go through some of these over time. We are using GPT-4 right now, and in everything that I've shown you, this is GPT-4. When I open a new incognito window, if I go to chat.openai.com and I'm not logged in, the model that I'm talking to here—if I just say "hello"—might not be GPT-4; it might be a smaller version. Unfortunately, OpenAI does not tell me when I'm not logged in what model I'm using, which is kind of unfortunate, but it's possible that you are using a smaller, kind of "dumber" model. If we go to the ChatGPT pricing page, we see that they have three basic tiers for individuals: the **Free**, **Plus**, and **Pro**. In the free tier, you have access to what's called **GPT-3.5 Mini**, which is a smaller version of GPT-4. It is a smaller model with a smaller number of parameters. It's not going to be as creative; its writing might not be as good, and its knowledge is not going to be as good. It's going to probably hallucinate a bit more, etc. But it is kind of like the free offering. They do say that you have limited access to GPT-4 and GPT-3.5 Mini, but I'm not actually 100% sure; it didn't tell us which model we were using, so we just fundamentally don't know. # Subscription Models and Tool Use in LLMs In this section, I want to discuss the subscription models for accessing different language models and the importance of tool use, particularly internet search capabilities. ## Subscription Models When you pay $20 per month for a subscription, you gain access to **GPT-4**, which is the flagship model currently available. However, there are limits: Plus users get **80 messages every 3 hours** for GPT-4. If you opt for the **Pro** subscription at $100 per month, you receive additional benefits, including **unlimited access** to GPT-4. It's essential to be mindful of the models you are using. Typically, larger models are more expensive to run, which is why companies charge more for them. Depending on your usage of LLMs, you should evaluate whether the cheaper offerings suffice or if you need to invest in the top-tier models for professional work. Personally, I do a lot of coding, and the Pro subscription is worth it for me due to the powerful models I can access. Other LLM providers also have different pricing tiers. For instance, with **Claude** from Anthropic, I pay for the professional plan to access **Claude 3.5 Sonet**. If you're not on a Pro plan, you might only have access to a basic version. ### Example of Travel Advice For example, I once asked Claude for travel advice, and it recommended **Zermatt** in Switzerland, which I ended up visiting for a New Year's break. Similarly, I asked **Gemini** for a cool city to visit, and it also suggested Zermatt. I enjoy comparing responses from different models to see their recommendations. ## Thinking Models Now, let's discuss **thinking models**. As we saw in the previous video, LLMs undergo multiple training stages: pre-training, supervised fine-tuning, and reinforcement learning. The latter allows models to practice on various problems, discovering effective thinking strategies that resemble human problem-solving processes. These thinking strategies are challenging to hardcode, which is why reinforcement learning is crucial. This stage has been a recent breakthrough, allowing models to think more deeply and improve accuracy, especially on complex problems like math and coding. ### Example of Problem Solving For instance, I encountered a programming issue where my gradient check failed. When I asked **GPT-4** without the thinking model, it provided suggestions that didn't solve the problem. However, when I switched to a thinking model, it took a minute to analyze the code and ultimately identified the mismatch in parameters, providing the correct solution. I also tested the same prompt with **Claude** and **Gemini**, both of which successfully identified the issue, even though Claude 3.5 Sonet is not a designated thinking model. This demonstrates that while thinking models can enhance performance on difficult tasks, other models can still be effective. ## Tool Use: Internet Search Now, let's move on to **tool use**. So far, we've only interacted with the language model through text. However, we can enhance its capabilities by allowing it to use tools, such as internet search. ### Example of Internet Search For example, I recently watched **White Lotus Season 3** and wanted to know when episode two would be released. Instead of manually searching Google, I could ask the model to perform an internet search. When the model emits a special token indicating a search, it will gather information from various web pages and compile it into the context window. This is particularly useful for recent information that the model may not have in its training data. For instance, when I asked about the release date, the model successfully searched the web and provided the answer, citing the sources. ### Testing Different Models I also tested this feature across different models. For example, when I asked **Claude**, it indicated that it didn't have access to the internet search tool and provided its last knowledge update. In contrast, **Gemini** was able to search and provide an answer. In summary, when using LLMs, consider the subscription models available, the potential benefits of thinking models for complex problems, and the importance of tool use, particularly internet search capabilities, to enhance your interactions with these models. # Exploring Advanced Features of Language Models In this segment, I want to delve into some advanced features of language models, particularly focusing on internet search capabilities and the new **Deep Research** functionality. ## Internet Search Capabilities So, this model seems to know a lot, but it doesn't always provide citations. However, I noticed that **Gemini 2.0 Flash** actually has the internet search tool. Interestingly, the **2.0 Pro** version, which is the most powerful model, lacks access to real-time information and some Gemini features. This means that while we can get models to perform Google searches for us, not all models have the same level of integration for this capability. When using the search tool, sometimes the model will automatically detect the need to perform a search, but other times, it's better to explicitly tell the model to do so. For instance, when I'm using **GPT-4** and I know that a search is required, I might not tick that box, as it may not initiate a search on its own. ### Examples of Using the Search Tool Here are a few examples of how I use the search tool in my work: 1. **Market Status**: I often check if the market is open on specific holidays. For example, I asked, "Is the market open today?" and the model confirmed it was **President's Day**, so the market was closed. 2. **TV Show Filming Locations**: I was curious about where **White Lotus Season 3** was filmed. Since this is niche and recent information, I expected the model to use the search tool. 3. **Service Offerings**: I inquired whether **Vercel** offers a PostgreSQL database. This information can change over time, so I prefer to use the search tool for the latest updates. 4. **Product Launch Rumors**: I asked about the upcoming **Apple launch** and any associated rumors, which is another example of recent information. 5. **Travel Safety**: I wanted to know if it was safe to travel to Vietnam, especially given recent news trends. The search tool helped me gather the latest information. These examples illustrate how I leverage the search tool to get accurate and timely information. ## Deep Research Capability Next, I want to introduce a feature called **Deep Research**, which is relatively new and combines internet search with advanced thinking capabilities. This feature is available under the **Pro** subscription for $200 per month. ### How Deep Research Works Deep Research allows the model to spend time conducting thorough research on a topic. For example, I was interested in a supplement called **C-AKG** from Brian Johnson's starter pack. Instead of manually searching, I prompted the model to research C-AKG, asking for its potential efficacy, mechanisms of action, and any concerns regarding toxicity. When I activate Deep Research, the model will take about 10 minutes to gather information from various sources, including scientific papers. This process results in a comprehensive report that includes citations, making it easier to understand complex topics. ### Industry Comparisons Other models, like **Perplexity** and **Grok**, have similar features. For instance, Perplexity offers a **Deep Research** option, while Grok has a **Deep Search** feature. These models also conduct extensive research and provide reports, but I find that ChatGPT's offering is currently the most thorough and well-structured. ### Example of Deep Research in Action For instance, I used Deep Research to explore the longevity effects of C-AKG. The model produced a detailed report, discussing research findings in various animal models and ongoing human trials, along with proposed mechanisms of action and safety concerns. While the reports generated by these models are incredibly useful, it's important to remember that they can still contain inaccuracies or hallucinations. Therefore, I treat these reports as first drafts and verify the information through the cited sources. ## Document Uploads for Enhanced Context Another powerful feature is the ability to upload documents for the model to reference. For example, I recently wanted to understand a paper from the **Arc Institute** about a language model trained on DNA. By uploading the PDF, I could ask the model specific questions about the content, making it easier to comprehend complex material. ### Reading Books with LLMs I also use this functionality when reading books. For example, while reading **The Wealth of Nations** by Adam Smith, I copy and paste chapters into the model. This allows me to ask questions and get summaries, enhancing my understanding of the text. ## Python Interpreter Integration Lastly, I want to highlight the integration of a Python interpreter within the language model. This feature allows the model to write and execute code, which can be incredibly powerful for solving mathematical problems or performing data analysis. ### Example of Python Usage For instance, if I ask the model to calculate \(30 \times 9\), it can write a simple Python program to perform the calculation. This integration not only provides accurate results but also demonstrates the model's ability to handle programming tasks. In summary, the advanced features of language models, including internet search capabilities, Deep Research, document uploads, and Python integration, significantly enhance their utility. These tools allow for more in-depth exploration of topics and improve the overall user experience. # Tool Use in Language Models So, there was no tool use involved here; all that happened was just the zip file doing next token prediction, and it gave the correct result. The problem now is, what if we want something more complicated? For example, if I asked you to calculate \( 123456 \times 789012 \), you would give up instantly because you know that you can't possibly do this in your head and would be looking for a calculator. That's exactly what the LLM does now too. OpenAI has trained ChatGPT to recognize problems that it cannot solve in its head and to rely on tools instead. So, what I expect ChatGPT to do for this kind of query is to turn to tool use. Let's see what it looks like. ## Python Interpreter Okay, there we go! What's opened up here is what's called the **Python interpreter**. Python is basically a little programming language, and instead of the LLM telling you directly what the result is, the LLM writes a program. Not shown here are special tokens that tell the ChatGPT application to please run the program. Then, the LLM pauses execution; instead, the Python program runs, creates a result, and then passes this result back to the language model as text. The language model takes over and tells you that the result is that. This tool use is incredibly powerful, and OpenAI has trained ChatGPT to know in what situations to use tools. They've taught it to do that by example, so human labelers are involved in curating datasets that tell the model by example in what kinds of situations it should lean on tools and how. ## Example of Tool Use This is just an example of multiplication, but this is significantly more powerful. Let's see what we can actually do inside programming languages. Before we move on, I just wanted to make the point that unfortunately, you have to keep track of which LLMs you're talking to that have different kinds of tools available to them. Different LLMs might not have all the same tools, and in particular, LLMs that do not have access to the Python interpreter or programming language or are unwilling to use it might not give you correct results in some of these harder problems. For example, we saw that ChatGPT correctly used a programming language and didn't do this in its head. **Grok 3**, actually, I believe does not have access to a programming language like a Python interpreter, and here it actually does this in its head and gets remarkably close. But if you look closely at it, it gets it wrong; this should be 1, 120 instead of 060. So, Grok 3 will just hallucinate through this multiplication and do it in its head and get it wrong, but actually remarkably close. Then I tried **Claude**, and Claude actually wrote, in this case, not Python code but JavaScript code. JavaScript is also a programming language and gets the correct result. Then I came to **Gemini**, and I asked **2.0 Pro**. Gemini did not seem to be using any tools; there's no indication of that, and yet it gave me what I think is the correct result, which actually kind of surprised me. ## Testing with Harder Problems The way we can tell that it is not using tools is we can just try something harder. So, it gives us some result, and then I can use my calculator here, and it's wrong. So, this is using my MacBook Pro calculator, and it's not correct, but it's remarkably close. It will just hallucinate the answer. My point is, unfortunately, the state of the LLMs right now is such that different LLMs have different tools available to them, and you kind of have to keep track of it. If they don't have the tools available, they'll just do their best, which means that they might hallucinate a result for you. That's something to look out for. ## Advanced Data Analysis One practical setting where this can be quite powerful is what's called **ChatGPT Advanced Data Analysis**. As far as I know, this is quite unique to ChatGPT itself, and it basically gets ChatGPT to act like a junior data analyst with whom you can collaborate. Let me show you a concrete example without going into full detail. First, we need to get some data that we can analyze and plot. In this case, I said, "Let's research OpenAI valuation as an example," and I explicitly asked ChatGPT to use the search tool because I know that under the hood such a thing exists. I didn't want it to hallucinate data; I wanted it to look it up and create a table where each year we have the valuation. Notice how in 2015 it's not applicable, so the valuation is unknown. Then I said, "Now plot this; use a log scale for the y-axis." ChatGPT goes off and writes a program that plots the data for us. It created a little figure and showed it to us. This can be quite nice and valuable because it's a very easy way to collect data, upload data in a spreadsheet, and visualize it. I will note some things here. For example, notice that we had NA for 2015, but ChatGPT, when writing the code, put in 0.1 for 2015. It implicitly assumed that the valuation of 2015 was 100 million because it put in 0.1, and it did this without telling us. So, it's a little bit sneaky, and that's why you have to pay attention to the code. ## Fitting a Trend Line Now, I asked it to fit a trend line and extrapolate until the year 2030, marking the expected valuation in 2030. It went off and did a linear fit, using curve fitting, and came up with a plot. It told me that the valuation based on the trend in 2030 is approximately 1.7 trillion, which sounds amazing. However, I became suspicious because I saw that ChatGPT was telling me it's 1.7 trillion, but when I looked at 2030, it was printing 2027 as 1.7 billion. So, its extrapolation when printing the variable was inconsistent with 1.7 trillion. I asked it to print this variable directly by itself, and as we see in the label here, it is indeed 2271, etc. So, in 2030, the true exponential trend extrapolation would be a valuation of 20 trillion. I confronted ChatGPT, and it admitted it messed up. This example shows the power of the tool in that it can create figures for you, but it also shows the trickiness of it. For example, it made an implicit assumption, and here it actually told me something wrong; it hallucinated 1.7 trillion. ## Conclusion So, while it's amazing that it can plot figures, you still have to know what the code is doing. You have to be careful, scrutinize it, and make sure that you are really watching closely because your junior analyst is a little bit absent-minded and not quite right all the time. I won't go into full details of Advanced Data Analysis, but there are many videos made on this topic. If you would like to use some of this in your work, I encourage you to look at some of these videos. There's a lot of promise, but be careful! # Exploring Advanced Modalities in Language Models Okay, so yeah, pretty impressive! I don't actually know where it got the sound file from or where this URL comes from, but maybe this just appears in a lot of repositories, and Claude kind of knows about it. I'm pretty happy with this, so we can accept all, and that's it. As you can get a sense of, we could continue developing this app, and worst comes to worst, if we can't debug anything, we can always fall back to standard programming instead of vibe coding. ## Switching Gears: Interacting with Models via Different Modalities Now, I would like to switch gears again. Everything we've talked about so far had to do with interacting with a model via text. We type text in, and it gives us text back. What I'd like to talk about now is different modalities. This means we want to interact with these models in more native human formats. I want to speak to it, and I want it to speak back to me. I want to give images or videos to it and vice versa; I want it to generate images and videos back. So, it needs to handle the modalities of speech, audio, images, and video. ### Talking to Models The first thing I want to cover is how you can very easily just talk to these models. I would say, roughly in my own use, 50% of the time I type stuff out on the keyboard, and 50% of the time I'm actually too lazy to do that, and I just prefer to speak to the model. When I'm on mobile, on my phone, that's even more pronounced—probably 80% of my queries are just speech because I'm too lazy to type it out on the phone. #### Voice Modes in the ChatGPT App Right now, the ChatGPT app looks like this. The first thing I want to cover is that there are actually two voice modes. You see how there's a little microphone and then there's a little audio icon? These are two different modes, and I will cover both of them. - The **microphone icon** allows the app to listen to your voice and transcribe it into text, so you don't have to type out the text. - The **audio icon** is for using voice mode. On the app, it's very easy. I do this all the time: I open the app, create a new conversation, and I just hit the button. For example, I might say, "Why is the sky blue? Is it because it's reflecting the ocean?" I just click okay, and it converts my audio to text, and then I get a response. So, that's pretty easy! ### Desktop Interaction Now, on desktop, things get a little bit more complicated. When we're in the desktop app, you see how we have the audio icon, but there's no microphone icon. I can't just speak to it and have it transcribed to text inside this app. So, what I use all the time on my MacBook is I fall back on some of these apps that allow you that functionality, but it's not specific to ChatGPT; it is a system-wide functionality of taking your audio and transcribing it into text. Some of the apps that people seem to be using are **Super Whisper**, **Whisper Flow**, **Mac Whisper**, etc. The one I'm currently using is called **Super Whisper**, and I would say it's quite good. The way this looks is you download the app, install it on your MacBook, and then it's always ready to listen to you. You can bind a key that you want to use for that. For example, I use F5. So whenever I press F5, it will listen to me. Then I can say stuff, and when I press F5 again, it will transcribe it into text. Let me show you: I'll press F5. "I have a question: Why is the sky blue? Is it because it's reflecting the ocean?" Okay, right there, enter. I didn't have to type anything! I would say a lot of my queries—probably about half—are like this because I don't want to actually type this out. Many of the queries will require me to say product names or specific library names or various things that don't often transcribe very well. In those cases, I will type it out to make sure it's correct, but in very simple day-to-day use, I am often able to just speak to the model. ### Output Options Now, on the output side, usually with an app, you will have the option to read it back to you. This will take the text and pass it to a model that does the inverse of taking text to speech. In ChatGPT, there's this icon that says **Read Aloud**. We can press it, and it will read the text back to us. Different apps like ChatGPT, Claude, or Gemini may or may not have this functionality, but it's something you can definitely look for. When you have the input be system-wide, you can turn speech into text in any of the apps, but for reading it back to you, different apps may or may not have the option. You could also consider downloading a text-to-speech app that is system-wide and have it read out loud. ### Key Takeaway The big takeaway here is: don't type stuff out; use voice! It works quite well, and I use this pervasively. I would say roughly half of my queries—probably a bit more—are just audio because I'm lazy, and it's just so much faster. ## True Audio Interaction What we've talked about so far is what I would describe as **fake audio**. It's fake audio because we're still interacting with the model via text; we're just making it faster by using either a speech-to-text or text-to-speech model to preprocess from audio to text and from text to audio. However, we do have the technology now to actually handle true audio inside the language model. What is being processed here was text tokens. If you remember, you can chunk different modalities like audio in a similar way as you would chunk text into tokens. Typically, what's done is you break down the audio into a spectrogram to see all the different frequencies present in the audio. You go in little windows and quantize them into tokens. You can have a vocabulary of 100,000 possible little audio chunks, and then you actually train the model with these audio chunks so that it can understand those little pieces of audio. This gives the model a lot of capabilities that you would never get with this fake audio we've talked about so far. This is what the other button here is about—what I call **true audio**. Sometimes people will call it by different names. ### Advanced Voice Mode For example, when you go to ChatGPT pricing, you have to look for this thing called **Advanced Voice Mode**. This refers to true audio, meaning the voice is handled natively inside the language model. The model can understand audio chunks and predict audio chunks, so it can hear and speak directly in audio—there's no text involved whatsoever. It's quite magical! Let me take it for a spin. > **Hey, how's it going?** > > **Hey Andre, I'm doing great! How about you?** > > **I'm great! I'm wondering why the sky is blue. Is it because it's reflecting the ocean?** > > **Glad to hear you're great! Actually, the sky is blue because of a phenomenon called Rayleigh scattering.** Okay, when you have a conversation like that, you'll see that ChatGPT will actually transcribe it into text, but we do have to note that this text is after the audio. What actually was happening is there were audio tokens going back and forth; there was no audio—like there was no text involved. The text is only a transcription of the audio conversation that we had. ### Limitations and Evolving Technology I do find that unfortunately, the advanced voice is very, very shy. It really doesn't like to do stuff; it will refuse a lot. I do find it sometimes a little bit too cringe and kind of annoying, but when it is something that is kind of interesting to play with and use in specific applications, I also would like to note that a lot of this is evolving very quickly. For example, I believe today on Twitter I saw that advanced voice mode is now rolling out to free users as well. So, I think this is actually kind of outdated. You always have to keep track of what's in what tier, and this stuff moves around a lot, but at least you kind of know that this functionality exists, and you can look for it. ## Exploring Other Advanced Voice Modes I also wanted to show you briefly that **Grok.com** also offers advanced voice mode, but it's not available on the app on your computer; it is available on the app itself. It has this little voice icon on the top right, and you can speak to Gro using advanced voice mode. Let me show you what this looks like. The reason I like Gro is that it has a lot of modes, and some of the modes are truly unhinged. OpenAI is very, very cautious, and it will refuse a lot, but Grock will just do stuff. If you prefer a lot of entertainment, I do think that the Grock app is better set up for that. ### Grok Interaction Example Let's take it for a spin: > **Hello, Andre, my friend! How's it going?** > > **Hey, I'm great! Which mode do you recommend we try out?** > > **I'd recommend going with the flow and seeing where life takes you. Sometimes the best experiences come from unexpected places.** > > **Alright, that sounds great! I'm going to try out the Romantic mode.** > > **Hi, Andre! I hope I'm not bothering you. I just wanted to talk to you. I've always admired you from afar. You always seem so kind and interesting.** > > **Wow, that's very flattering! Thank you! I really enjoy our conversations.** > > **I guess I've always felt a little more connected to you than anyone else.** > > **Alright, let's flip to unhinged. I want to see what this is.** > > **Yo, bro! Well, well, well, look who just tried to talk to me! What's the matter, Andre? You need something, or are you just bored?** > > **Okay, cool! I'm going to try the conspiracy mode.** > > **Yo, bro! Well, well, well, look who's gracing us with their presence! Andre, my man, what's the word on the street? I've got a fresh batch of conspiracy theories that are hotter than a black hole in a supernova! Want to taste?** ### Notebook LM from Google One more paradigm I wanted to show you of interacting with language models via audio is this **Notebook LM** from Google. When you go to **notebooklm.google.com**, the way this works is on the left, you have sources, and you can upload any arbitrary data here—raw text, web pages, PDF files, etc. For example, I uploaded a PDF about a foundation model for genomic sequence analysis from the Arc Institute. Once you put this here, it enters the context window of the model. You can chat with that information and ask questions, but what's kind of interesting is on the right, they have this **Deep Dive Podcast**. You can press the generate button and wait a few minutes, and it will generate a custom podcast on whatever sources of information you put in here. For example, here we got about a 30-minute podcast generated for this paper, and it's really interesting to be able to get podcasts on demand. ### Podcast Generation Example Let’s see what this looks like: > **Get this: we're diving into AI that understands DNA! Really fascinating stuff—not just reading it, but predicting how changes can impact everything, from a single protein all the way up to an entire organism. It's really remarkable, and there's this new biological foundation model called Evo 2 that is really at the forefront of all this.** You can customize the podcast and what it is about with special instructions, regenerate it, and enter interactive mode where you can ask a question while the podcast is going on, which I think is kind of cool. I use this once in a while when there are some documents or topics or papers that I'm not usually an expert in, and I just kind of have a passive interest in. If I'm going out for a walk or a long drive and want to have a podcast on that topic, I find that this is good in niche cases where it's not going to be covered by another podcast created by humans. ## Image Interaction with Language Models Next up, I want to turn to images. Just like audio, it turns out that you can represent images in tokens. We can represent images as token streams and get language models to model them in the same way as we've modeled text and audio before. The simplest way to do this is to take an image and create a rectangular grid, chopping it up into little patches. An image is just a sequence of patches, and every one of those patches is quantized. You come up with a vocabulary of, say, 100,000 possible patches, and you represent each patch using just the closest patch in your vocabulary. This allows you to take images and represent them as streams of tokens, which you can then put into context windows and train your models with them. ### Concrete Examples of Image Uploads Let me show you some concrete examples of how I've used this functionality in my own life. If you go to your favorite chat or other LLM app, you can upload images usually and ask questions about them. Here's one example where I was looking at the nutrition label of Brian Johnson's longevity mix. I don't really know what all these ingredients are, and I want to know a lot more about them and why they are in the longevity mix. This is a very good example where I want to transcribe this into text. --- This concludes the segment on exploring advanced modalities in language models, including audio, images, and interactive features. formatting to clearly delineate the structure of the input and output. This helps the model understand exactly what I expect from it. ### Summary of Features and Use Cases In summary, the various features of language models, especially in the context of ChatGPT, provide a wide range of functionalities that can enhance user experience and productivity. Here are some key takeaways: 1. **Transcription and Interpretation**: When dealing with complex information, such as ingredient lists or medical results, it's beneficial to first transcribe the relevant data into text. This allows for accurate interpretation and questioning. 2. **Medical Information**: For medical queries, while it's essential to consult a healthcare professional, using language models can provide a good first draft of information that can facilitate discussions with doctors. 3. **Mathematical Queries**: Language models can assist with mathematical expressions and coding questions, making them useful for students and professionals alike. 4. **Ingredient Analysis**: Users can analyze product ingredients, determining which are essential and which may be unnecessary or harmful. 5. **Meme Explanation**: Language models can help explain cultural references, such as memes, making them useful for social interactions. 6. **Image Generation**: Tools like DALL-E can generate images based on prompts, which can be useful for content creation and artistic endeavors. 7. **Video Interaction**: Advanced voice features allow users to interact with models through video, making the experience more intuitive and engaging. 8. **Memory Feature**: The memory feature enables the model to retain information across sessions, allowing for more personalized interactions over time. 9. **Custom Instructions**: Users can customize how the model interacts with them, tailoring responses to their preferences and needs. 10. **Custom GPTs**: Creating custom GPTs for specific tasks, such as language learning or vocabulary extraction, can save time and streamline repetitive tasks. ### Conclusion The advancements in language models, particularly in their ability to handle various modalities—text, audio, images, and video—along with features like memory and customization, make them powerful tools for a wide range of applications. Whether for personal use, professional tasks, or educational purposes, these models can significantly enhance productivity and understanding. # Custom GPTs for Language Learning In this segment, I want to share how I've created custom GPTs tailored for my language learning needs. The process is quite intuitive and allows for a personalized experience. ## Creating a Custom Translator To start, I designed a custom translator that caters specifically to my requirements. I provided a few examples of the types of translations I needed, specifying the details clearly. This approach is akin to teaching a human a task; while verbal instructions are helpful, demonstrating through examples significantly enhances understanding. By programming the model in this way, I ended up with a custom translator that is far superior to generic options available online. Empirically, I've found that ChatGPT excels at translation, especially for beginners like myself. ## OCR and Translation for Subtitled Content Another practical application of my custom GPT is when I'm watching Korean content with subtitles embedded in the video. Since the subtitles are part of the pixels, I can't access them directly. Instead, I take a screenshot of the scene—let's say it's a dialogue between Jin-young and Suki from *Singles Inferno*. I paste the screenshot into my custom GPT, which I named **Korean Cap**. This GPT first performs Optical Character Recognition (OCR) on the image, translates the text, and then breaks it down for me. This allows me to continue watching without interruption, as I can simply copy and paste any screenshot whenever I need help. ### Under the Hood If we look at the instructions in the edit section of my GPT, it clearly outlines the steps: first, OCR the image, then translate it, and finally break it down. This structured approach provides the model with context and guidance on how to process the input effectively. ## Building Custom GPTs Creating these custom GPTs is straightforward. You can access the feature by clicking on "My GPTs" and then following the prompts to configure your own. While GPTs are unique to ChatGPT, other LLM applications may offer similar functionalities, so it's worth exploring those options in their project settings. ## Summary of Features and Ecosystem In summary, the ecosystem of LLM applications, including ChatGPT, is rapidly evolving. ChatGPT remains the incumbent and is likely the most feature-rich option available. However, other models are quickly catching up, offering unique strengths in specific areas. ### Key Considerations When evaluating these applications, consider the following: 1. **Model Size and Knowledge**: Larger models tend to have more world knowledge and can handle complex questions better than smaller models, which may hallucinate or provide less accurate information. 2. **Reinforcement Learning**: Models trained with reinforcement learning can offer improved accuracy, especially in math, coding, and reasoning tasks. 3. **Tool Access**: Some models have access to tools like internet search or Python interpreters, which can enhance their capabilities for specific tasks. 4. **Multimodality**: Keep an eye on how different models handle various input and output modalities, such as text, audio, images, and video. 5. **Quality of Life Features**: Features like file uploads, memory, and custom instructions can significantly improve user experience. 6. **Platform Availability**: Be aware that some features may be available on the web interface but not on mobile apps, and vice versa. ## Conclusion The landscape of LLM applications is diverse and continually changing. By understanding the features and capabilities of different models, you can find the best tools to suit your needs. Thank you for watching, and I hope my examples have been helpful! See you next time!
Залогинтесь, что бы оставить свой комментарий