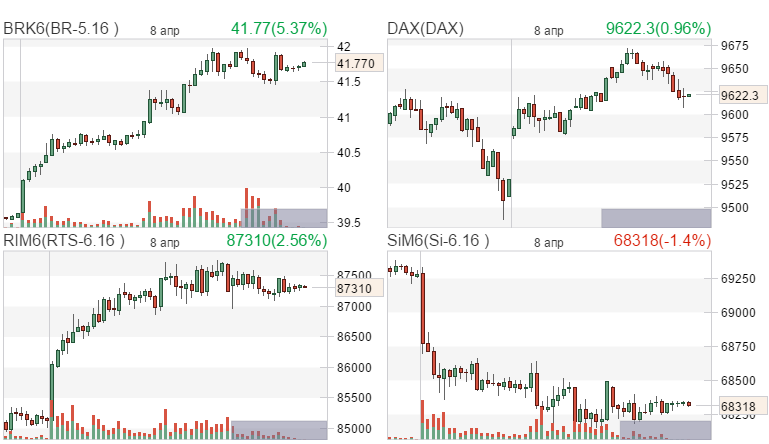
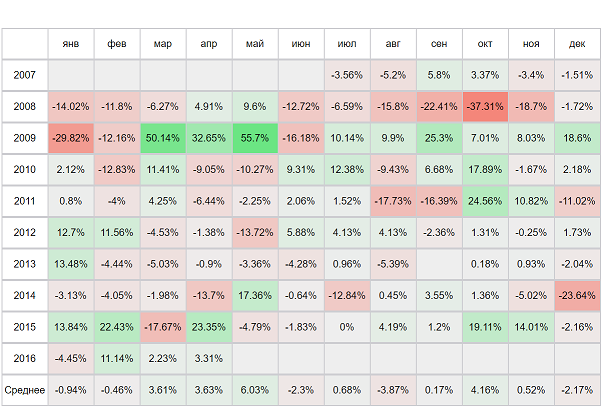
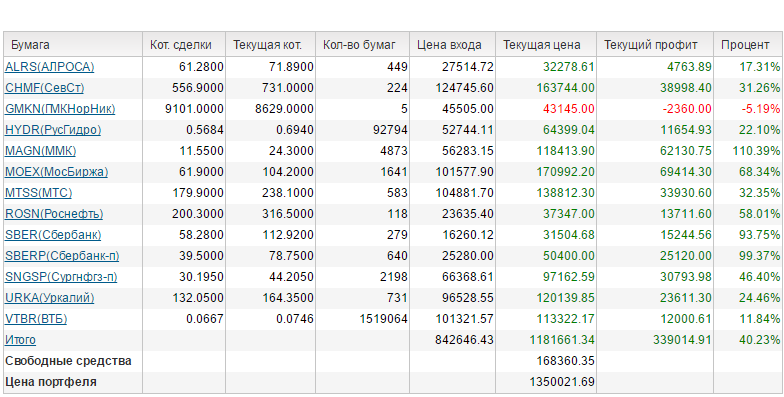
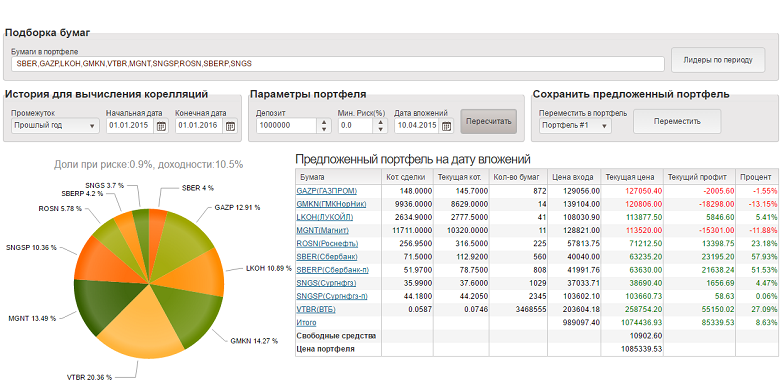
 | | | |||||||||||
|
|
||||||||||||
| | | |||||||||||||||
|
|
||||||||||||||||



Техническая поддержка
ONLINE
| | | |||||||||||||||||
|
|
||||||||||||||||||
MIT Introduction to Deep Learning | 6.S191
ruticker 06.03.2025 8:52:41 Recognized text from YouScriptor channel Alexander Amini
Recognized from a YouTube video by YouScriptor.com, For more details, follow the link MIT Introduction to Deep Learning | 6.S191
**Good afternoon everyone!** Thank you for joining us today. My name is **Alexander Amini**, and together with **Ava**, we're going to be your instructors for the course this year. This is **MIT Introduction to Deep Learning**, or **6.S191**, which is our official course title. Now, we're super excited to welcome you to this class, and I think probably a good place to start is always asking ourselves, "What is MIT Intro to Deep Learning?" This is a **one-week boot camp** on everything deep learning, right? So, it's both a very fun but also a very intense week because we're going to cover a ton of material in just the next five days. This is our **eighth year** teaching this class, and the pace of the field, especially in the past couple of years, is really remarkable. Every time we teach this class, it’s getting more and more interesting to introduce this lecture in particular, and how we introduce this lecture has really started to adapt and evolve over the many years. Many of you in the audience have probably even started to become almost a bit desensitized to a lot of the progress of deep learning in the past couple of years because of how rapidly this progress is happening. So, I think it's also important to not forget where we came from just a few years ago. I want to show you this image right here just to start this off. What better way to show you than for you to actually see the progress with your own eyes? Exactly one decade ago, this was the state-of-the-art deep learning-based facial generation system. So, this is not a real face; this was the best that we could do. Fast forward just a few years down the pipeline, and progress in image generation had already started to advance tremendously. Here you can see a lot more realism, photo-realism, in these types of images being created. Then, fast forward another few years after that, and these images start to come to life. They start to have temporal information; they start to have video and movement as well. In fact, this video that you see on the right is a video that we created in this class some years ago. For those of you who haven't seen it already, it's online, and people have seen it, but in case you haven't, I'll play just the first 10 seconds. I won't play the whole thing, just so you can see it as well. *Hi everybody and welcome to MIT 6.S191, the official introductory course on deep learning taught here at MIT.* Now, when we did this in 2020, it got a lot of attention. Especially back then, maybe you guys aren't that impressed by it today, but back then, this video was a huge deal. This was a huge jump in photo-realism for the capabilities of deep learning models. The clip went very rapidly viral, and people commented a lot about the realism. But actually, one interesting thing that people didn't see was that for us to generate that clip, which was a two-minute clip—you only saw the first 10 seconds—but that clip was two minutes in total. To generate that two-minute clip, it cost around **two hours** of professional audio data being recorded and captured of the speaker, which was not us. It cost around **50 hours** of professional high-definition video data to build the face model, and it required around **$155,000** US dollars of compute to generate that two-minute video. All of that was just to generate a predefined script—something static. You couldn't talk to it; you couldn't interact with it. It was just a predefined script, static, not flexible at all. But still, a tremendous amount of resources—both time, data, energy, and financial resources as well. I wanted to start this class by basically asking the question of, "What would this look like today?" That video was created in 2020, but today we're in 2025. What would cloning and generative AI look like in today's world, especially understanding all of those limitations that we had back then in 2020? I thought, what better way to tell you about this than to just show you? Instead of all of that compute and resources that we spent in 2020, let's do it live and unedited right in front of everybody today. So, in fact, I have a bit of a secret. I'm going to share my other screen and move this over. This is a terminal window that you can actually see. Something's been recording audio in the background as I've been talking. I've been having this program that we made listening to my audio, recording my voice, and what I'm going to do is just pause the recording now, and we're going to see how quickly it can actually immediately start to just take my voice and do an instant clone, as opposed to all of that time-intensive resources that we saw before. *I'll pause it right now. You'll see it instantly clone... and yeah, now my voice is cloned!* What we're going to do with this is actually try and not have a predefined script like we saw before. I'm going to actually have a live and unedited conversation with this voice and see how dynamic and flexible these types of generative AI models have become in today's world. So, let's try this out. *Hello, can you hear me?* *Hi, yes, loud and clear! How are you doing?* *Wait a second, actually, you sound a lot like me, don't you?* *That's interesting! You're right; we're even more similar than I thought. What are we up to?* *Well, actually, I was just kicking off this year's MIT deep learning class, and you know, I'm standing right in front of the audience right now. MIT Introduction to Deep Learning is such a great class! What's the class like so far?* *Actually, we just started. You know what? I had an idea, so I was just about to introduce what is deep learning. How about you take that part over for me?* *Deep learning is a type of machine learning that uses artificial neural networks to learn from data. These networks are inspired by the structure of the human brain and are able to learn complex patterns from large amounts of data. Deep learning is used in a wide range of applications, including image recognition, natural language processing, and self-driving cars.* *It's pretty good, actually! You know, I think the amazing thing I was telling everybody in the audience about was that the state of deep learning today is so flexible; it's so dynamic. What do you think?* *You're right! Deep learning is incredibly dynamic. It's constantly evolving with new architectures, algorithms, and applications being developed all the time. Actually, wait, let me interrupt you right there just to show how dynamic you are. I'm going to interrupt you, and let's try this: enough about deep learning! How about you tell me a story about turtles and make it wild?* *Oh, turtles! You want the wild turtle story? Okay, picture this: there's this turtle named Shell, right? He's not your average turtle. Oh no! Shell's got dreams. He dreams of flying! He spends his days practicing flapping his little flippers, trying to get off the ground. One day, he meets this crazy inventor, a mad scientist turtle named Dr. Sheldon, who's built a rocket-powered shell. Shelly jumps in, and boom! They blast off into space! They zoom past planets and meet aliens who love to eat...* *I'll interrupt you one more time. It's turtle-tastic! Oh, let's end it here!* *Okay, thank you so much! This was a cool way to introduce the class. I'm glad I could help!* *Okay, thanks! Bye-bye!* *Bye!* Okay, awesome! That's just a fun way to show you how far we've come in this field, you know, just from a few years ago generating very static content, and now, live, unedited, extremely dynamic content as well. So, you actually just heard a very brief introduction on what deep learning is. In fact, in that demo, and all of the progress that all of you have been seeing over the past many years, you'll see in this class over the next week the fundamental techniques that drive all of that progress. Let's just start by maybe laying some foundation, laying some groundwork on exactly what this field is all about. To do that, I think first I have to introduce to you what is **intelligence**. First of all, to me, the word intelligence means the ability to process information in order to inform some future decision, right? Some future action. This is what intelligence means. All of us exhibit this capability every single day, you know, some more than others. But **artificial intelligence** is just the practice of building algorithms—artificial algorithms—to do exactly that same process: use information, use data to inform future decisions. Now, **machine learning**—what is machine learning? Machine learning is a subset of artificial intelligence that focuses on not explicitly programming the computer how to use that data, how to process that information to inform that decision, but just trying to learn some patterns within the data to make those decisions. Finally, **deep learning** is just a subset of machine learning, which focuses on doing that exact process with neural networks—deep neural networks. We'll learn exactly what deep neural networks are throughout this class. But really, at a high level, this entire course is about this core idea fundamentally. This is what we will teach, and you will all get a very strong handle on throughout this entire week: you will learn how to teach computers how to learn how to do tasks directly from observation, directly from data. We'll provide you both a solid foundation in the lectures but also through practical understanding in software labs as well, so you can get very hands-on. That's probably a good segue to tell you a little bit about the entire course at a high level. This is going to be a combination, like I said, between the technical lectures and the software labs. We'll have several new updates this year in particular, as the field is advancing so quickly. We're really going to try to drive home a lot of key points, especially in more of the modern side of deep learning. To that end, we'll conclude with some guest lectures from industry leaders on state-of-the-art deep learning methods and AI methods that are being developed in the industry. This will really start to advance your knowledge even more. In addition, yes, that's right! Also tonight, we're going to have a reception at **4:30 PM**, and you are all invited to that reception as well to talk to everyone and learn more about deep learning. There's also food provided! This year, we also have a lot of great updates on the software labs. We'll be introducing both **TensorFlow** and **PyTorch** software labs. These are, number one, a great learning experience for all of you to get hands-on with everything that you learn in the lectures, but also they're a medium for you to enter into the competition prizes and make yourselves eligible for a lot of cash prizes at the end of this course. So how exactly does that work? Each day, we'll have a dedicated lecture, and we'll have a dedicated software lab that mirrors that lecture. The software lab will just basically reinforce what has been taught during the day in the lectures. Starting today, you'll have **Lab 1**, where you're going to focus on building a form of a language model. Actually, it'll be a very small language model, but it's a next-token predictor language model that learns how to generate music and predict the next token of music so you can generate novel folk songs. Then tomorrow, we'll move on to facial detection systems. You'll get hands-on with building your own computer vision system from scratch, understanding also some automated techniques to fix imbalanced data in those systems. Finally, **Lab 3** is going to be a brand new lab premiering this year for the first time on large language models. You're actually going to, in that part of the lab, fine-tune a **two billion parameter** large language model on compute that you'll control in a mystery style, and you'll also build an AI judge to evaluate the quality of that language model. All three of these labs are going to be a lot of fun! Finally, on the last day of the class, we'll have a **final project pitch competition**. Each group can consist of up to **three to five people**, and each group is presenting up to **three to five minutes** in a shark tank-style pitch competition. Then you'll be eligible for even more prizes as part of that as well. Okay, I won't go through this slide. There are many great resources available as part of this class. This slide, as well as the entire lectures, are all posted online. You can already check the website; they should be online already. If you ever need any help, please post on **Piazza** if you have any questions. We have a team of incredible TAs and instructors this year that you can reach out to at any time for any questions or issues. Myself and Ava will be your two main lecturers for most of the course, but then you will also be hearing from a lot of guest lecturers throughout the rest of the class. Here are some of the names. This course, in general, would not have been possible each of these years without all of our amazing sponsors, so I do want to give a huge thank you for all of their support over the years. Now that we've gone through all of that, I want to start with a lot of the fun stuff! Yeah, go ahead, sure! Yeah, that's right! This course has been taught for **eight years**. We've taught it to over around **13 million people**. Just at MIT alone, because MIT has a global audience, the MIT audience is around probably **3,000** at this point, and every year online, around **100,000** people take this class. So, you're in great company, and a lot of really amazing people have taken this class. We're really excited for all of you to be here today! So, I want to start now, as we dive into the technical part of this class, by really asking this fundamental question: **Why deep learning, and why now?** Hopefully, this is a question all of you have asked before you came here today. Understanding exactly what gets at the basis of deep learning is really important so that we can understand how we can move forward and build even better algorithms that drive this field. Traditional machine learning, maybe if we start there for a second, typically defines what are called **sets of features**. I'll tell you more about that word in a second, but usually, what these features are—these are basically rules of how to do a task step by step. The problem is that if we as humans define those features, we're not usually very good at building very robust features. For example, let's say I wanted to tell you, or I told you to build an AI model that could detect faces. How would you do this? What features would you build in an image to detect faces? Well, what you could do is you could start by first detecting lines in the image—just edges, right? Very simple lines. Then you could start to compose those lines together to detect things like curves and edges, and then you can combine those together to start to form more composite objects, like eyes, noses, and ears. From there, you can actually start to build up structures of faces. Why would you do it like this? Well, it's actually naturally, hopefully, the way that you would also think of doing it because it's very hard to immediately just one-shot detect a face. You actually don't process faces like this. First of all, you actually start by processing much more high-level features first, then you compose these together to really form your own intuition about a face. Now, the key idea of deep learning is no different than this process. The key idea is to learn these features instead of me telling you or you telling me exactly what those features are. The key idea of deep learning is to say, "After observing a lot of faces, can I learn that I should first detect things in this hierarchical fashion step by step? First detect the lines, then detect the curves, then detect the composites like eyes, noses, and ears, and then build up to facial structure like this?" It turns out this is exactly what deep learning is able to do, and we'll see how this is being done underneath the hood throughout this lecture. It's really important to understand, though, that even though we are seeing so many of these amazing things in deep learning over the past few years, everything that you'll learn, especially in today's lecture—this is an intro lecture—almost everything that you'll see today has been invented or developed decades ago. This is not a new thing. New things that we'll be showing in today's lecture, tomorrow, and the day after, and after that, you'll start to see a lot more of the recent advances. But why are we seeing this all today? The reason is because, number one, we see an explosion of these techniques—even the techniques that are decades old—because of three key components. Number one is **data**. Data is becoming more and more plentiful throughout the world, and this is really driving deep learning progress. **Compute** is number two. Compute is becoming more and more powerful and more and more commoditized. GPU architectures, especially, are driving the progress in learning, and GPUs were only recently starting to be commoditized. Finally, **open-source toolboxes** like you see on the right-hand side—TensorFlow, PyTorch, Keras, and so on—make it very streamlined and very easy for all of you, just in a one-week course, to get hands-on with these architectures and start to build directly. So, let's start by understanding the fundamental building blocks of every neural network, and that's just a single neuron or a **perceptron**. What is a perceptron? The idea of a perceptron or a single neuron is really simple. Let's start by just taking and defining a perceptron purely by its forward propagation of information. Given some inputs, how does a perceptron compute an output? Let's start by defining a set of inputs \(X_1\) to \(X_M\), and each of these numbers—each of these inputs—will be multiplied by a corresponding weight \(W_1\) through \(W_M\). What we're going to do is, after we do this multiplication, we're going to add up all of those numbers together. We'll take the single number that comes out and then we'll pass it through what's called a **nonlinear activation function**. This is just a nonlinear one-dimensional function that you can pass through. This single number on the output here is denoted as... minimum. This process is known as **gradient descent**. In gradient descent, we iteratively adjust our weights \(W\) in the direction that reduces the loss \(L\). The size of each step we take is determined by a parameter called the **learning rate**. If the learning rate is too small, the training process will be slow; if it's too large, we risk overshooting the minimum and potentially diverging. Now, let's summarize the key steps in training a neural network: 1. **Initialize Weights**: Start with random weights for the network. 2. **Forward Pass**: Compute the output of the network given the input data. 3. **Compute Loss**: Calculate the loss using the predicted output and the true labels. 4. **Backward Pass**: Compute the gradient of the loss with respect to each weight using backpropagation. 5. **Update Weights**: Adjust the weights in the opposite direction of the gradient by a factor of the learning rate. 6. **Repeat**: Continue this process for a number of iterations or until the loss converges. This iterative process allows the model to learn from the data and improve its predictions over time. As we move forward in this course, you'll see how these concepts are applied in practice, and you'll gain hands-on experience with implementing these techniques in your software labs. Now, let's take a moment to discuss some common challenges you might encounter while training neural networks. 1. **Overfitting**: This occurs when the model learns the training data too well, including its noise and outliers, which can lead to poor generalization on unseen data. Techniques like regularization, dropout, and early stopping can help mitigate overfitting. 2. **Underfitting**: This happens when the model is too simple to capture the underlying patterns in the data. Increasing the model complexity or adding more features can help address underfitting. 3. **Vanishing/Exploding Gradients**: In very deep networks, gradients can become very small (vanishing) or very large (exploding), making training difficult. Techniques like batch normalization and using appropriate activation functions can help alleviate these issues. 4. **Choosing Hyperparameters**: The performance of a neural network can be sensitive to the choice of hyperparameters, such as learning rate, batch size, and the number of layers. Techniques like grid search or random search can be used to find optimal hyperparameters. As we wrap up this introduction, I encourage you to think about the applications of deep learning in various fields, from healthcare to finance to entertainment. The potential is vast, and the skills you acquire in this course will empower you to contribute to this exciting field. Thank you for your attention, and I look forward to seeing you in the labs and lectures throughout the week! **Local Minimum** We can summarize this algorithm, this procedure, as what's known as **gradient descent** in pseudo code. Let's go through it again one more time very briefly. 1. **Initialize Weights**: Start by randomly initializing our weights. This means that we randomly pick a place in our landscape. 2. **Compute Gradient**: We compute the gradient here, denoted as \( \frac{dJ}{dW} \). This tells us how much a small change in our weights changes our loss. It indicates the direction that we should change our weights in order to increase our loss. 3. **Update Weights**: We take a small step in the opposite direction. Here, we take that gradient, multiply it by negative one, and go in the opposite direction. We then multiply it by a small step, let's call it \( \alpha \) (the learning rate), which dictates how much we move in that direction. 4. **Repeat**: We repeat this in a loop over and over again. In TensorFlow, you can see this represented the same way, but I want to draw your attention to this term: the direction term. The gradient tells us which direction is going up or down if we take the negative of it. However, I never actually told you how to compute this gradient. The process of computing the gradient in a neural network is called **backpropagation**. ### Backpropagation Example Let's take a quick step-by-step example to walk through how backpropagation works and how you would compute this gradient for a particular neural network. We'll start with the simplest neural network that exists: it consists of one input, one output, and one hidden neuron in the middle. We want to compute the gradient of our loss \( L \) (or \( J \)) at the end with respect to \( W_2 \). This tells us how much a small change in \( W_2 \) affects our loss. We can write out this derivative in math and use the **chain rule** to decompose it. We decompose this gradient \( \frac{dJ}{dW_2} \) into two terms: \( \frac{dJ}{dY} \) and \( \frac{dY}{dW_2} \). This is just a basic extension of the chain rule—nothing magical here. Now, if we wanted to compute the gradients of the weight before \( W_2 \), let's say \( W_1 \), we can replace \( W_2 \) in this equation with \( W_1 \) and apply the chain rule again. This is why we call it **backpropagation**: you start from the output and compute these iterative chain rules back through the network step by step. At the end of this process, for every single weight in our network, we have a direction indicating whether increasing that weight will cause our loss to go up or down. If our loss decreases, we should increase that weight a little bit; otherwise, we go in the opposite direction. ### Practical Implications In practice, today's deep learning frameworks like TensorFlow and PyTorch do this automatically, so you don't necessarily need to implement this yourself. However, it's important to understand the theoretical side of how these things operate and what they're doing underneath the hood. Optimizing neural networks is extremely difficult. Neural networks exist in high-dimensional search spaces, and this is a projection of the loss landscape of a deep neural network. You can visualize how messy some of these loss landscapes look, making the application of backpropagation and optimization techniques very challenging. ### Learning Rate Now, let's focus on the learning rate, which dictates how quickly we take those steps and how quickly we listen to our gradients during backpropagation. Setting the learning rate can be very difficult. If it's too slow, we may get stuck in local minima that aren't the best. If it's too large, we risk unstable behavior, overshooting, and diverging. To set the learning rate, one option is to try a bunch of learning rates to see what works best. A more sophisticated approach is to design adaptive algorithms that change the learning rate based on the optimization landscape. This means your learning rate can increase or decrease as a function of your gradients and data. ### Adaptive Learning Rate Schedulers Many adaptive learning rate schedulers have been created, such as **Adam**. These algorithms adjust the learning rate based on the optimization process, allowing for more efficient training. ### Stochastic Gradient Descent Now, let's dig into the difference between **gradient descent** and **stochastic gradient descent (SGD)**. The gradient in gradient descent is computed as a summation over all data points in the dataset, which is computationally expensive. In most real-life problems, it's not feasible to compute the gradient over the entire dataset on every iteration. Instead, in SGD, we compute a noisy gradient based on just one data point. This allows us to get through more steps quickly, but it introduces noise. To balance speed and accuracy, we can use **mini-batch gradient descent**, where we compute the gradient over a small batch of data points (e.g., 32 or 128). This provides a more reliable gradient while still being faster than full gradient descent. ### Overfitting and Regularization Now, let's touch on **overfitting** and **regularization**. In machine learning, we want models that generalize well to unseen data, not just perform well on the training set. Overfitting occurs when a model learns the training data too well, including its noise, which can hurt performance on new data. For example, if you have a small dataset but a large network, the model may memorize the training data, leading to poor generalization. **Regularization** techniques, such as **Dropout**, help discourage complex memorization. During training, we randomly set some activations of hidden neurons to zero, forcing the network to learn multiple pathways and not rely too heavily on any one neuron. Another technique is **early stopping**, where we monitor the training and validation loss. If the validation loss starts to increase while the training loss continues to decrease, we stop training to prevent overfitting. ### Conclusion In summary, understanding these concepts—gradient descent, backpropagation, learning rates, stochastic gradient descent, and regularization—is crucial for effectively training neural networks. As you progress through this course, you'll gain hands-on experience with these techniques and learn how to apply them in practice. Approximate, uh, no, so the drop nodes will not have gradients because we don't have, uh, information about what's happening with them. But for all of the other nodes, we'll get an update. Yes, exactly! For this to work, it should be separate. Yeah, so this is a key assumption: ideally, you take your training data, and what people can do is basically cut your training data in a ratio. Right? So, let's say you take **70%** of your training data and actually use it for training; you take the other **30%** of your training data and use it for testing and validation. Right? Okay, last question: do you feel a difference in loss between the testing and training datasets? Great question! Um, I mean, there's no ideal, right? Ideally, actually, there would be no difference. Right? In practice, though, there are situations where there is very little difference. Let me give an example: assume your training set is so massive that it's impossible for your model to learn the full capacity; it's impossible for the model to memorize. Then, actually, you will see that the training and testing losses are very close to each other. A good example of this is **language modeling**. Even massive language models still have trouble memorizing the entire dataset just because language is such a massive dataset, right? So, even there, basically, you'll see training and testing curves look very, very similar. But that's why we have to actually do other types of validation. Language models don't really have the classical overfitting problems that, you know, other types of deep learning models have. They have other problems, which we'll talk about. Yeah, okay, awesome! Okay, I'll conclude now just by summarizing the three points that we talked about in this lecture before we jump into lecture number two. First, we talked about building neural networks—the architectures of neural networks. We talked about the base operation; the base architecture is called a **perceptron**, a single neuron. We learned about how we could stack those single neurons together to form complex hierarchical networks and how we can mathematically optimize those networks using data. Finally, we addressed a lot of the practical implications, everything from batch gradient descent to overfitting and regularization and optimization of these models. In the next lecture, we're going to hear from **Ava** on **deep sequence modeling**, which is the backbone of large language models. This is a really exciting type of lecture, so hopefully, everyone enjoys it! I think probably what we'll do is just take a **five-minute break** so AA and I can switch laptops, and then we will continue with the lecture. After the lecture, we have software labs followed by a reception with food. Okay, thanks, everyone!
Залогинтесь, что бы оставить свой комментарий